探索 Edge Craft RAG¶
在 UI 中使用 LLM 进行 ChatQnA 示例¶
创建流水线¶
要创建默认流水线,请在 Pipeline Setting(流水线设置)页面点击 Create Pipeline 按钮。
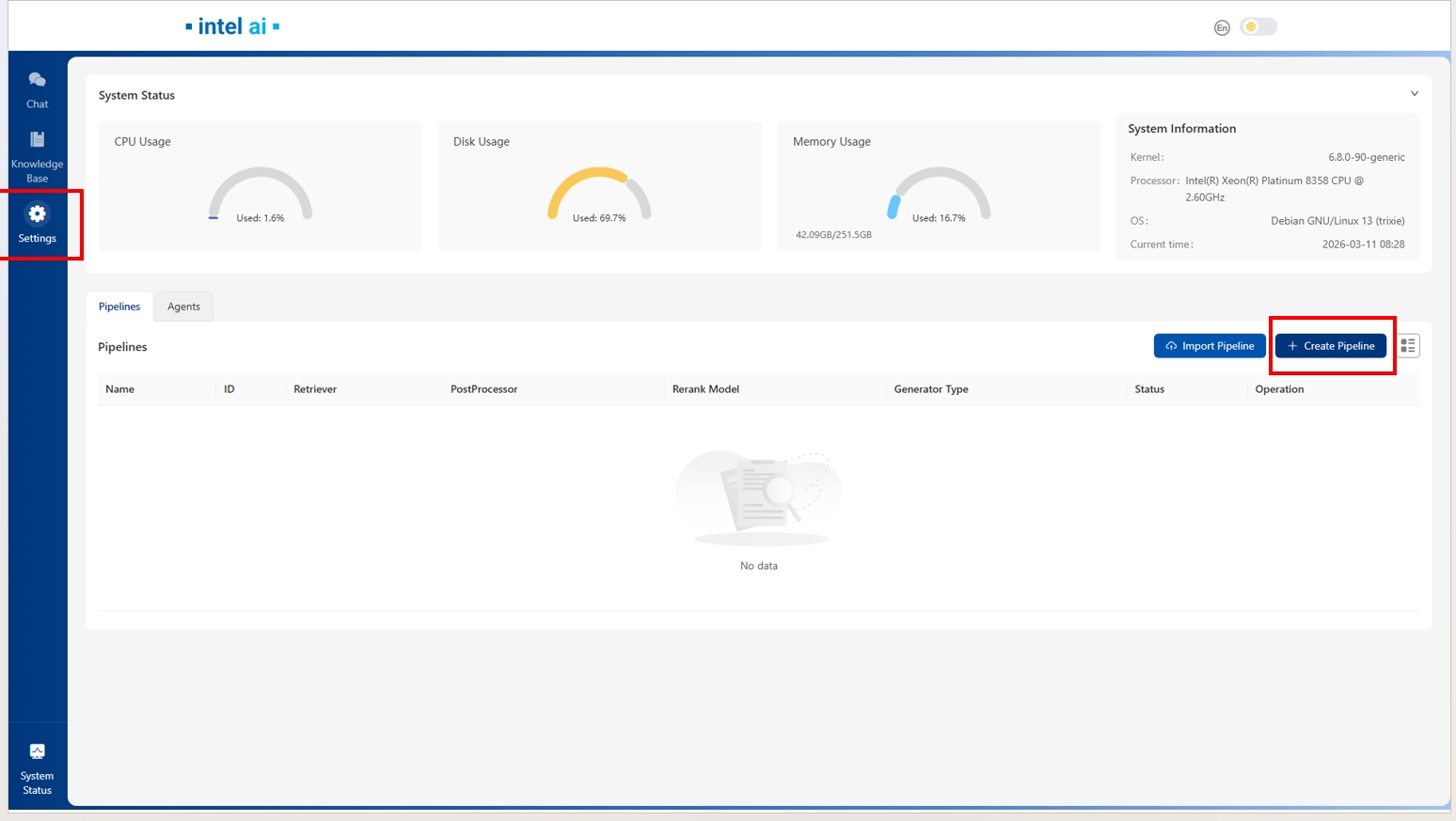
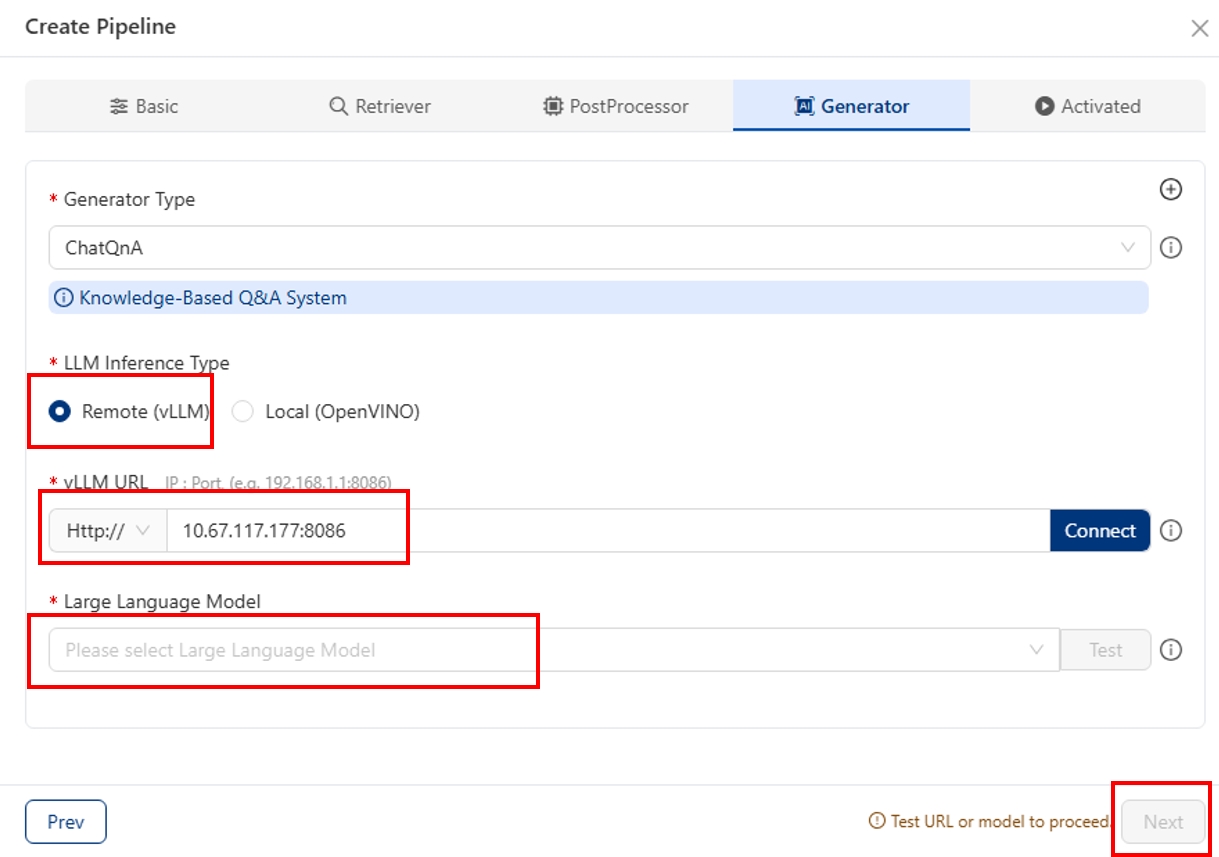
然后,在 Generator(生成器)配置页面,将 LLM Inference Type 选择为 Vllm。
在 Large Language Model 字段中输入您的 LLM 模型名称,例如 Qwen/Qwen3-8B。
在 Vllm Url 字段中输入 IP:vllm_port,然后点击 Test 按钮。注意 vllm_port 默认为 8086。
(注意:如果测试失败,可能是因为 vLLM 服务尚未就绪,可等待 30 秒后重试。)
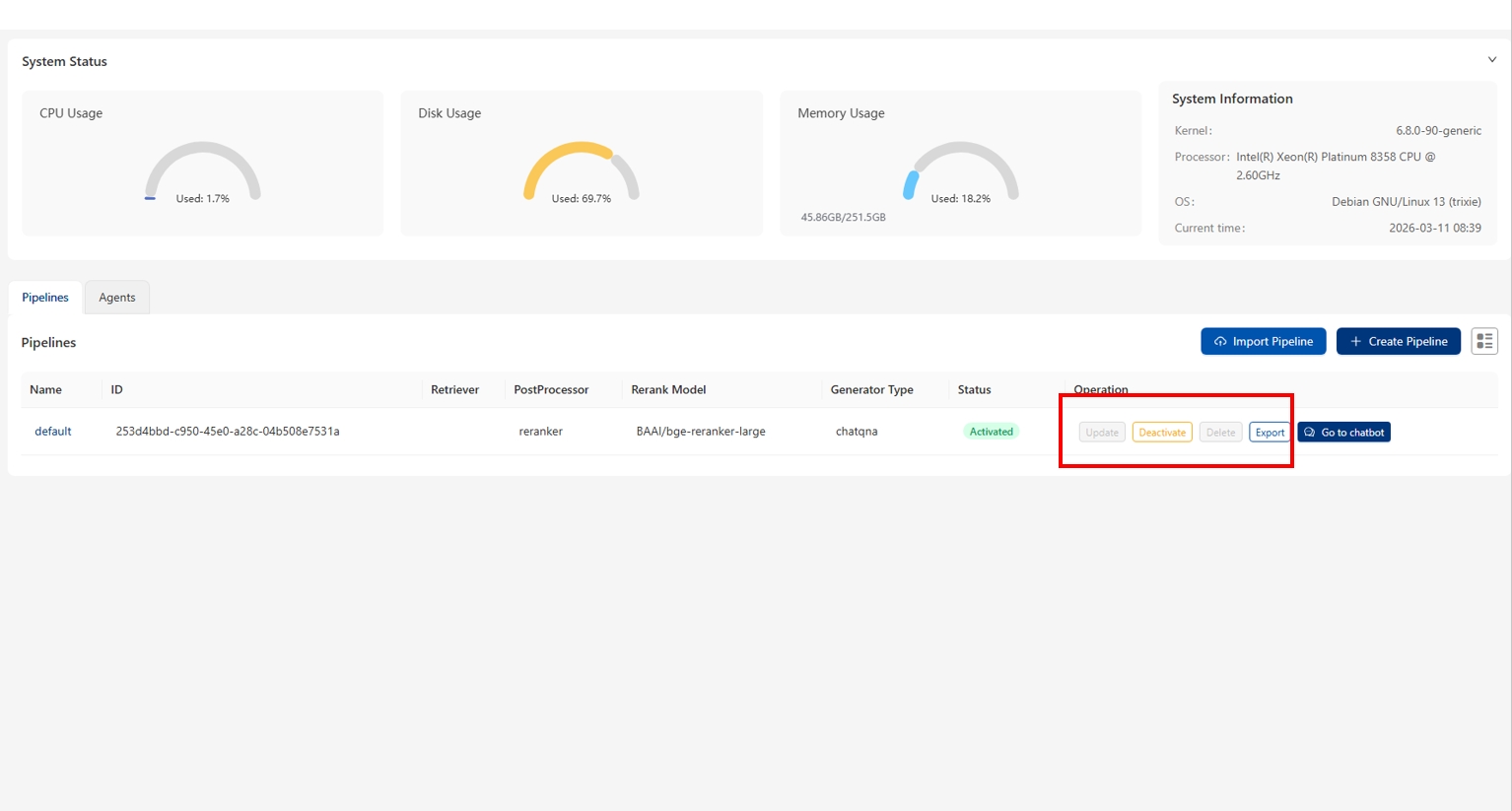
您也可以通过 Operation 字段创建多条流水线或更新/删除已有流水线,但请注意处于激活状态的流水线无法被更新。
上传文件与 ChatQnA¶
流水线创建完成后,前往 Knowledge Base(知识库)页面,点击 Create Knowledge Base 按钮创建知识库。
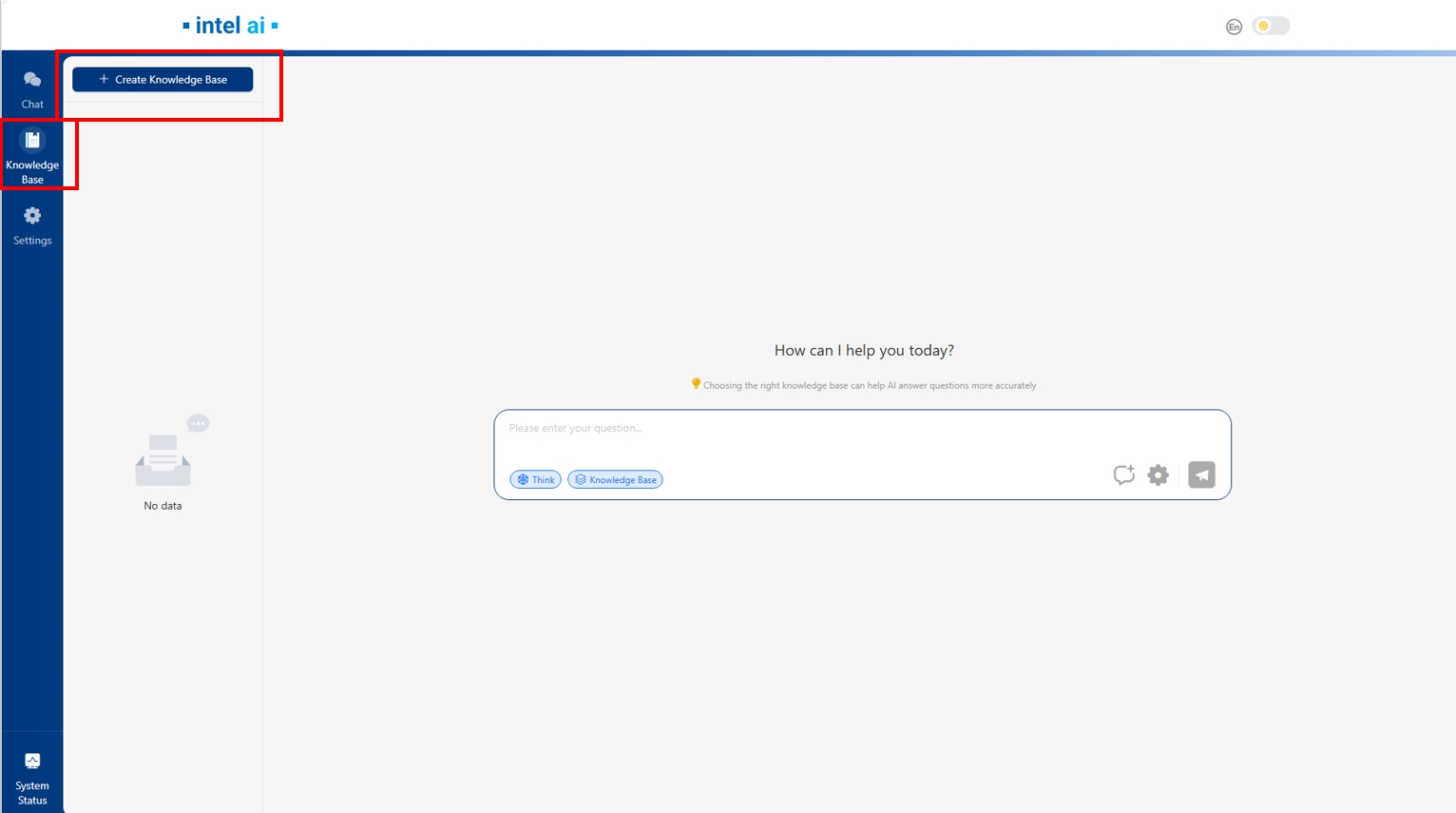
然后按照 UI 中的知识库创建向导进行配置。请注意,在 Indexer Type(索引器类型)中可以选择 MilvusVector 作为索引器(请确保在选择 MilvusVector 之前已启用 Milvus,可参考 启用 Milvus)。
如果选择 MilvusVector,需要先验证向量数据库 URI,请输入 Your_IP:milvus_port,然后点击 Test 按钮。注意 milvus_port 默认为 19530。
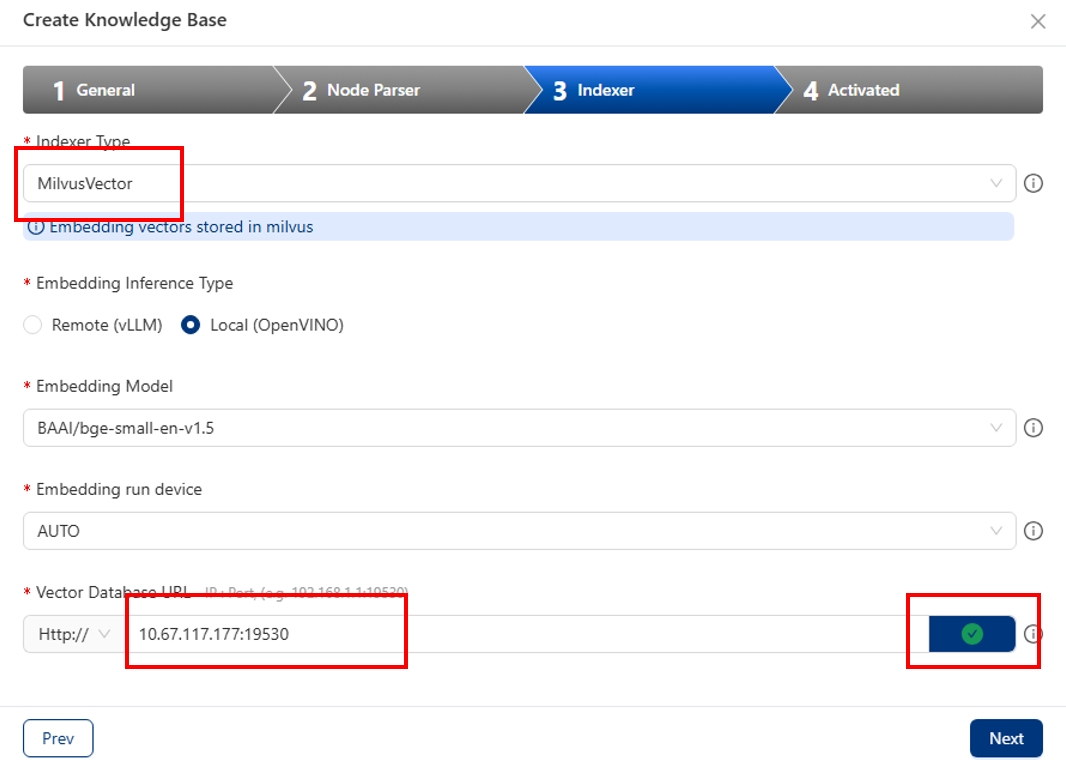
创建知识库时,请选择 Activated(激活)选项,只有处于激活状态的知识库中的文件才能在 ChatQnA 中被检索。
知识库创建完成后,即可上传用于检索的文档。

然后,在 Chat 页面的聊天框中提交您的问题。
在 UI 中使用 Kbadmin 进行 ChatQnA¶
Kbadmin 知识库¶
流水线创建完成后,前往 Knowledge Base 页面,点击 Create Knowledge Base 按钮创建知识库。
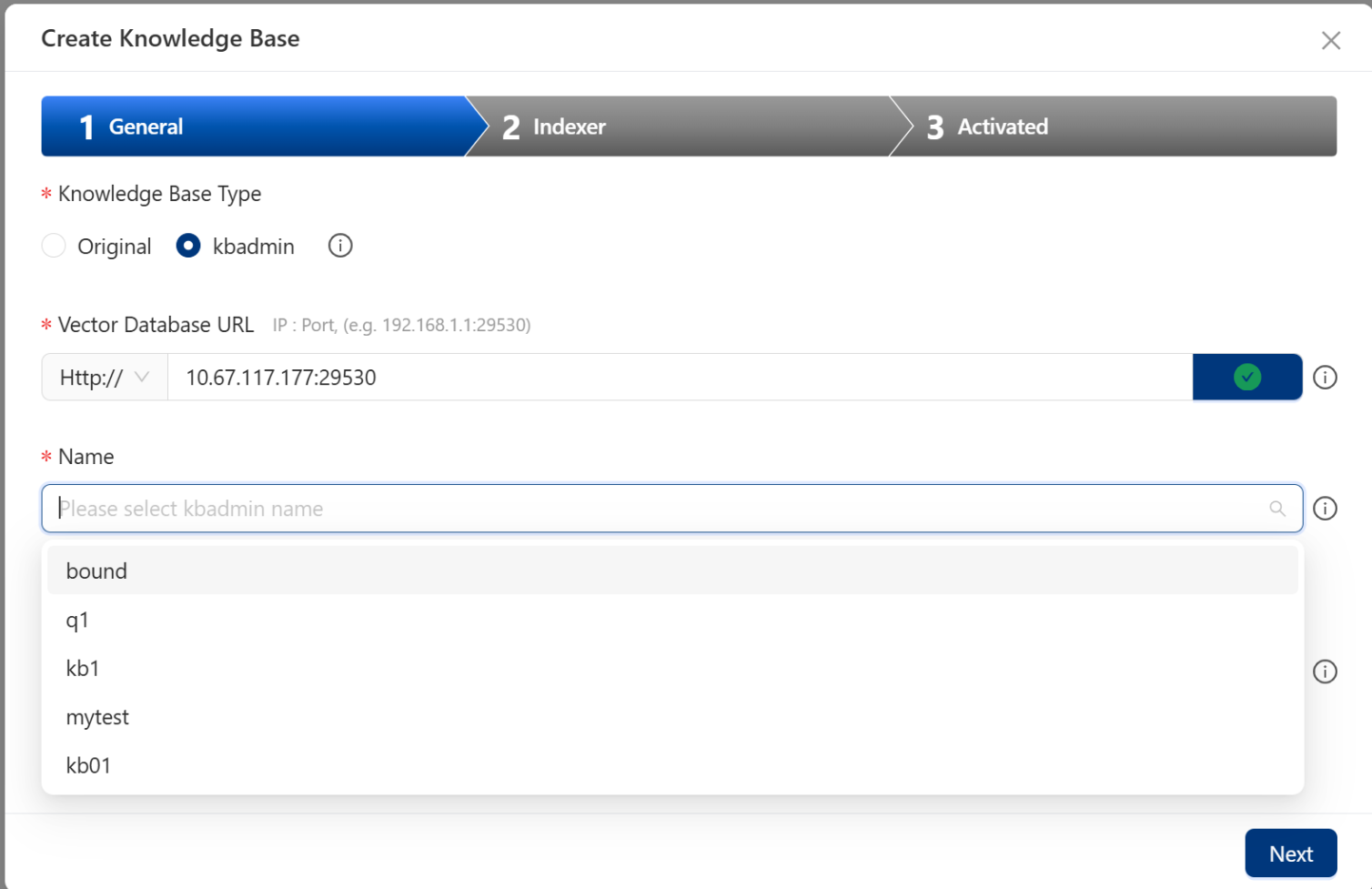
请在 Type 中选择 kbadmin,并从 kbadmin UI 页面中已创建的知识库列表中选择 kb 名称。加载kb名称可能比较耗时,请耐心等待。
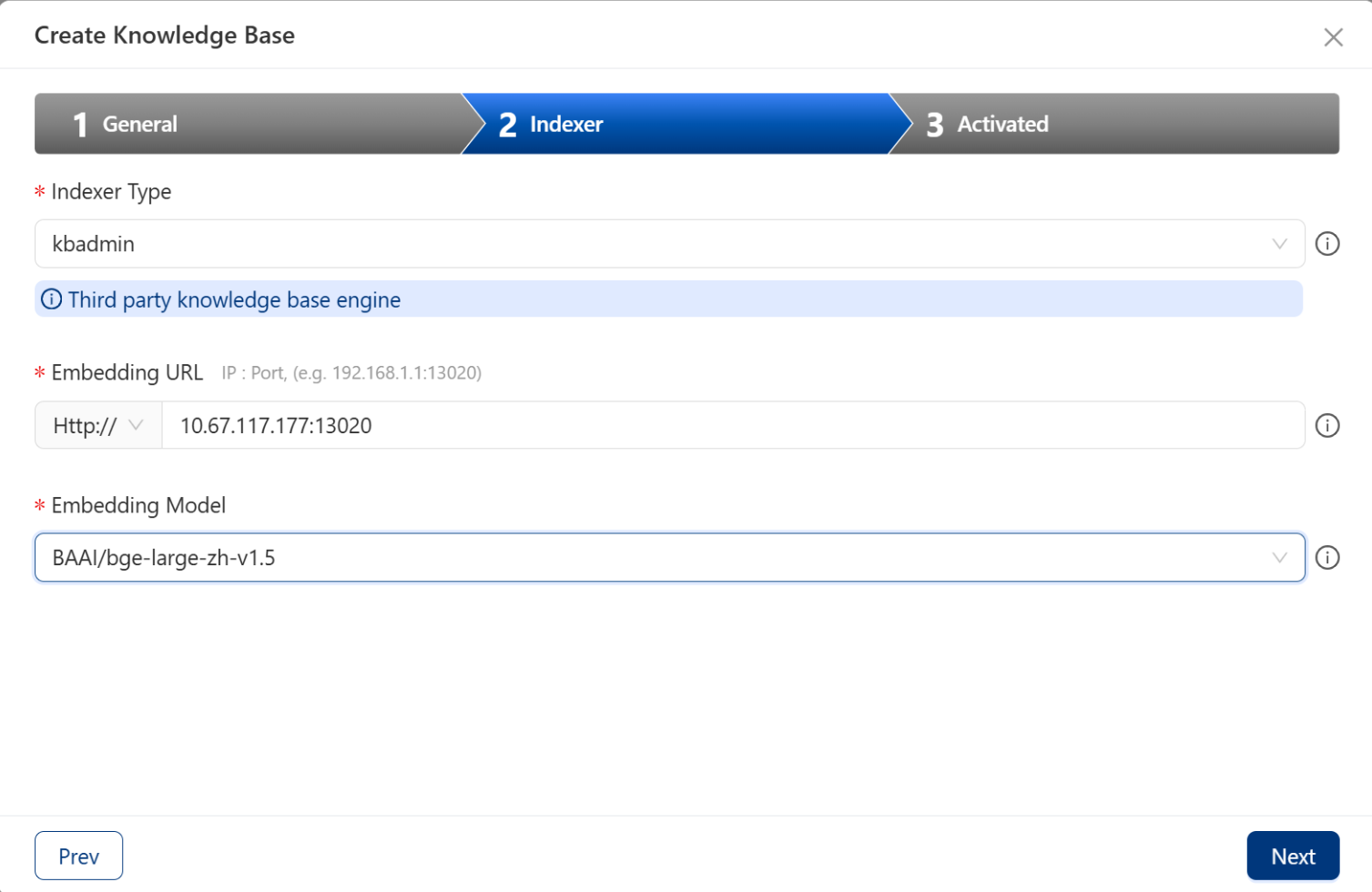
在 Indexer 页面,填写 Embedding 服务和向量数据库信息,注意 Embedding 服务端口为 13020,向量数据库端口为 29530。
然后,在 Chat 页面的聊天框中提交您的问题。