ChatQnA Application¶
Chatbots are the most widely adopted use case for leveraging the powerful chat and reasoning capabilities of large language models (LLMs). The retrieval augmented generation (RAG) architecture is quickly becoming the industry standard for chatbot development. It combines the benefits of a knowledge base (via a vector store) and generative models to reduce hallucinations, maintain up-to-date information, and leverage domain-specific knowledge.
RAG bridges the knowledge gap by dynamically fetching relevant information from external sources, ensuring that the response generated remains factual and current. Vector databases are at the core of this architecture, enabling efficient retrieval of semantically relevant information. These databases store data as vectors, allowing RAG to swiftly access the most pertinent documents or data points based on semantic similarity.
Table of contents¶
Architecture¶
The ChatQnA application is a customizable end-to-end workflow that leverages the capabilities of LLMs and RAG efficiently. ChatQnA architecture is shown below:
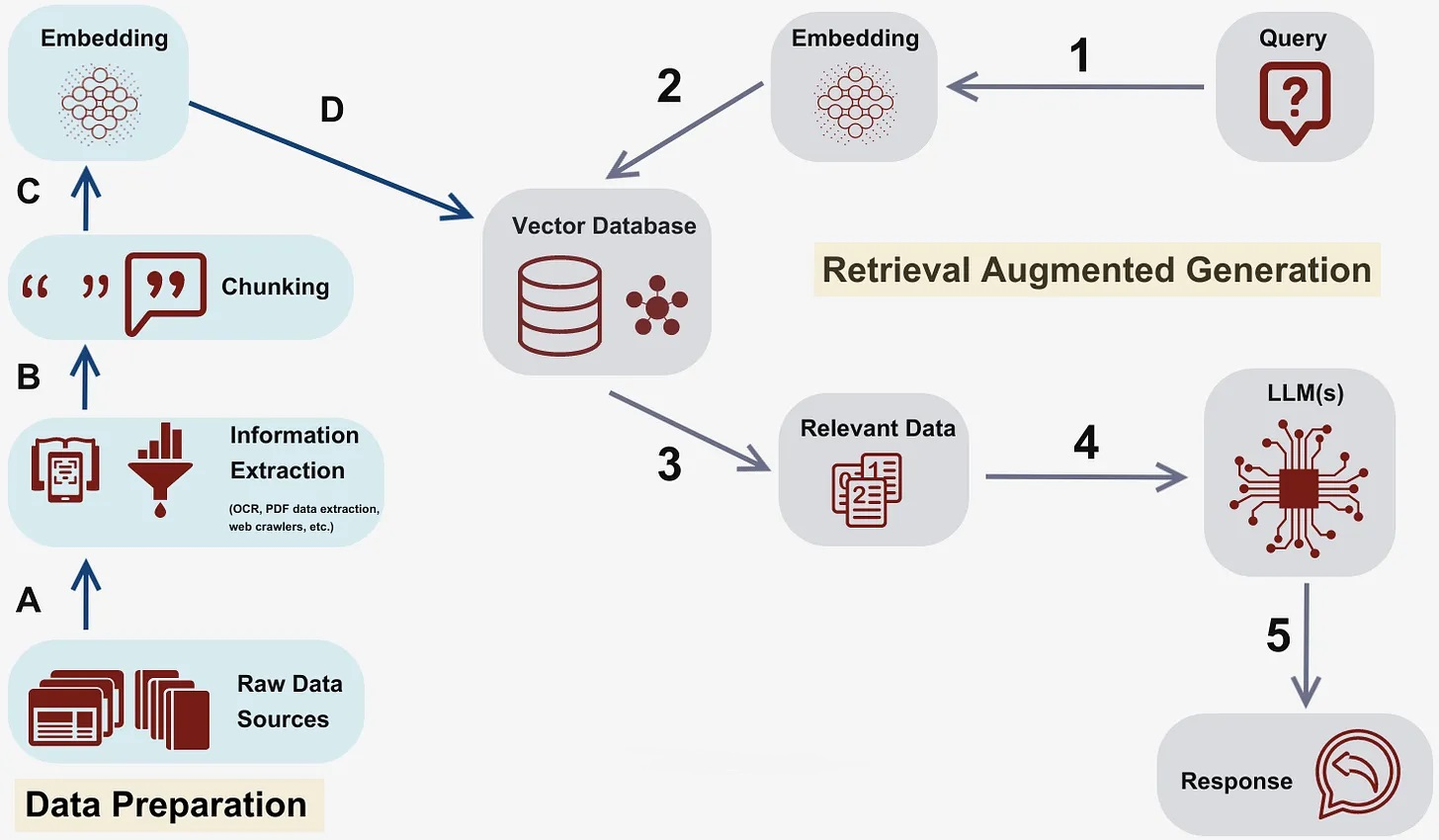
This application is modular as it leverages each component as a microservice(as defined in GenAIComps) that can scale independently. It comprises data preparation, embedding, retrieval, reranker(optional) and LLM microservices. All these microservices are stitched together by the ChatQnA megaservice that orchestrates the data through these microservices. The flow chart below shows the information flow between different microservices for this example.
Deployment Options¶
The table below lists currently available deployment options. They outline in detail the implementation of this example on selected hardware.
Category |
Deployment Option |
Description |
|---|---|---|
On-premise Deployments |
Docker compose |
|
Cloud Platforms Deployment on AWS, GCP, Azure, IBM Cloud,Oracle Cloud, Intel® Tiber™ AI Cloud |
Docker Compose |
Getting Started Guide: Deploy the ChatQnA application across multiple cloud platforms |
Kubernetes |
||
Automated Terraform Deployment on Cloud Service Providers |
AWS |
Terraform deployment on 4th Gen Intel Xeon with Intel AMX using meta-llama/Meta-Llama-3-8B-Instruct |
Terraform deployment on 4th Gen Intel Xeon with Intel AMX using TII Falcon2-11B |
||
GCP |
||
Azure |
Terraform deployment on 4th/5th Gen Intel Xeon with Intel AMX & Intel TDX |
|
Intel Tiber AI Cloud |
Coming Soon |
|
Any Xeon based Ubuntu system |
ChatQnA Ansible Module for Ubuntu 20.04. Use this if you are not using Terraform and have provisioned your system either manually or with another tool, including directly on bare metal. |
Monitor and Tracing¶
Follow OpenTelemetry OPEA Guide to understand how to use OpenTelemetry tracing and metrics in OPEA.
For ChatQnA specific tracing and metrics monitoring, follow OpenTelemetry on ChatQnA section.
FAQ Generation Application¶
FAQ Generation Application leverages the power of large language models (LLMs) to revolutionize the way you interact with and comprehend complex textual data. By harnessing cutting-edge natural language processing techniques, our application can automatically generate comprehensive and natural-sounding frequently asked questions (FAQs) from your documents, legal texts, customer queries, and other sources. We merged the FaqGen into the ChatQnA example, which utilize LangChain to implement FAQ Generation and facilitate LLM inference using Text Generation Inference on Intel Xeon and Gaudi2 processors.
Validated Configurations¶
Deploy Method |
LLM Engine |
LLM Model |
Embedding |
Vector Database |
Reranking |
Guardrails |
Hardware |
|---|---|---|---|---|---|---|---|
Docker Compose |
vLLM, TGI |
meta-llama/Meta-Llama-3-8B-Instruct |
TEI |
Redis |
w/, w/o |
w/, w/o |
Intel Gaudi |
Docker Compose |
vLLM, TGI |
meta-llama/Meta-Llama-3-8B-Instruct |
TEI |
Redis, Mariadb, Milvus, Pinecone, Qdrant |
w/, w/o |
w/o |
Intel Xeon |
Docker Compose |
Ollama |
llama3.2 |
TEI |
Redis |
w/ |
w/o |
Intel AIPC |
Docker Compose |
vLLM, TGI |
meta-llama/Meta-Llama-3-8B-Instruct |
TEI |
Redis |
w/ |
w/o |
AMD ROCm |
Helm Charts |
vLLM, TGI |
meta-llama/Meta-Llama-3-8B-Instruct |
TEI |
Redis |
w/, w/o |
w/, w/o |
Intel Gaudi |
Helm Charts |
vLLM, TGI |
meta-llama/Meta-Llama-3-8B-Instruct |
TEI |
Redis, Milvus, Qdrant |
w/, w/o |
w/o |
Intel Xeon |