Code Generation Example (CodeGen)¶
Table of Contents¶
Overview¶
The Code Generation (CodeGen) example demonstrates an AI application designed to assist developers by generating computer code based on natural language prompts or existing code context. It leverages Large Language Models (LLMs) trained on vast datasets of repositories, documentation, and code for programming.
This example showcases how developers can quickly deploy and utilize a CodeGen service, potentially integrating it into their IDEs or development workflows to accelerate tasks like code completion, translation, summarization, refactoring, and error detection.
Problem Motivation¶
Writing, understanding, and maintaining code can be time-consuming and complex. Developers often perform repetitive coding tasks, struggle with translating between languages, or need assistance understanding large codebases. CodeGen LLMs address this by automating code generation, providing intelligent suggestions, and assisting with various code-related tasks, thereby boosting productivity and reducing development friction. This OPEA example provides a blueprint for deploying such capabilities using optimized components.
Architecture¶
High-Level Diagram¶
The CodeGen application follows a microservice-based architecture enabling scalability and flexibility. User requests are processed through a gateway, which orchestrates interactions between various backend services, including the core LLM for code generation and potentially retrieval-augmented generation (RAG) components for context-aware responses.
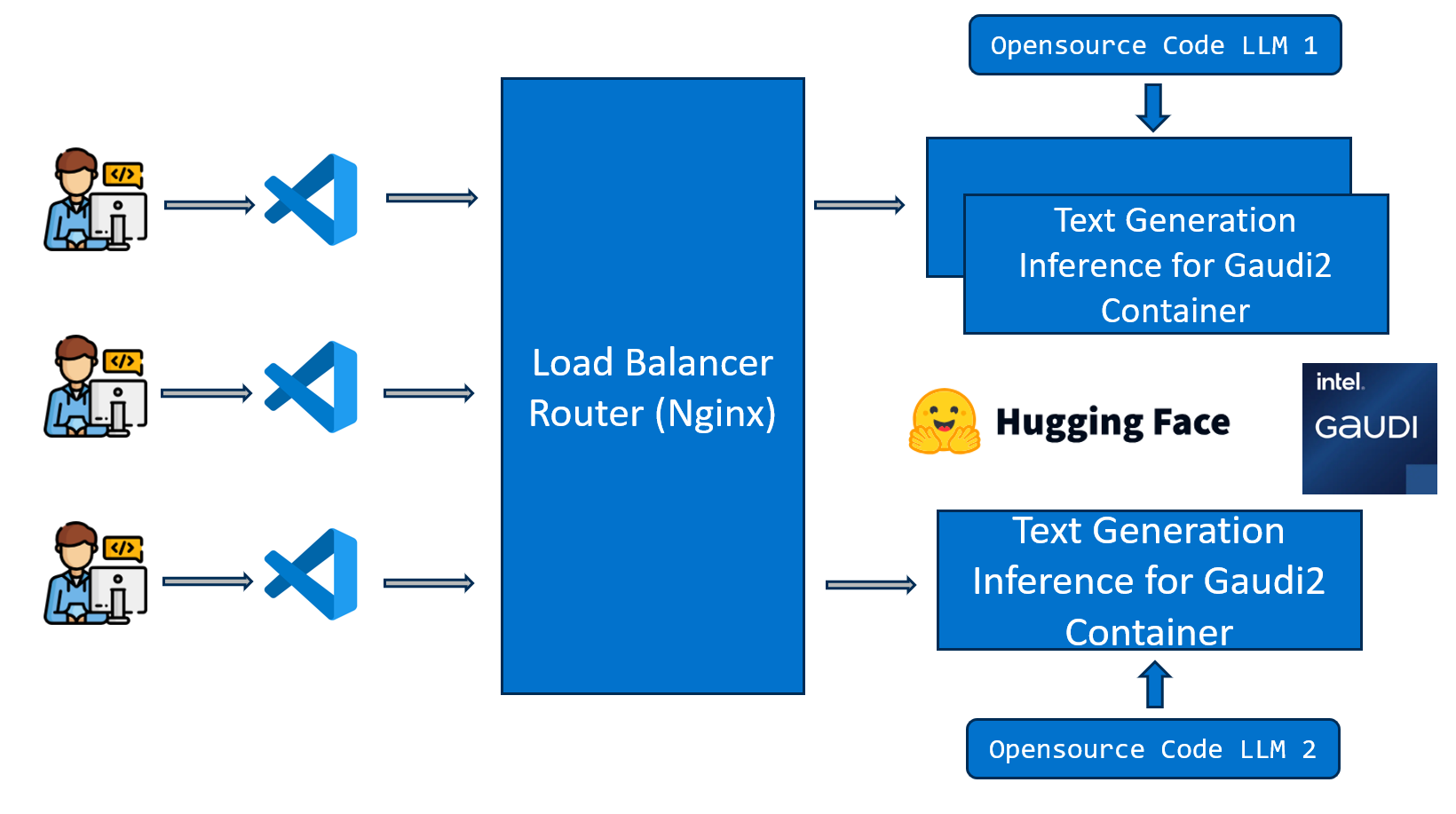
OPEA Microservices Diagram¶
This example utilizes several microservices from the OPEA GenAIComps repository. The diagram below illustrates the interaction between these components for a typical CodeGen request, potentially involving RAG using a vector database.
Deployment Options¶
This CodeGen example can be deployed manually on various hardware platforms using Docker Compose or Kubernetes. Select the appropriate guide based on your target environment:
Hardware |
Deployment Mode |
Guide Link |
|---|---|---|
Intel Xeon CPU |
Single Node (Docker) |
|
Intel Xeon CPU |
Single Node (Docker) with Monitoring |
|
Intel Gaudi HPU |
Single Node (Docker) |
|
Intel Gaudi HPU |
Single Node (Docker) with Monitoring |
|
AMD EPYC CPU |
Single Node (Docker) |
|
AMD ROCm GPU |
Single Node (Docker) |
|
Intel Xeon CPU |
Kubernetes (Helm) |
|
Intel Gaudi HPU |
Kubernetes (Helm) |
|
Intel Xeon CPU |
Kubernetes (GMC) |
|
Intel Gaudi HPU |
Kubernetes (GMC) |
Note: Building custom microservice images can be done using the resources in GenAIComps.
Monitoring¶
The CodeGen example supports monitoring capabilities for Intel Xeon and Intel Gaudi platforms. Monitoring includes:
Prometheus: For metrics collection and querying
Grafana: For visualization and dashboards
Node Exporter: For system metrics collection
Monitoring Features¶
Real-time metrics collection from all CodeGen microservices
Pre-configured dashboards for:
vLLM/TGI performance metrics
CodeGen MegaService metrics
System resource utilization
Node-level metrics
Enabling Monitoring¶
Monitoring can be enabled by using the compose.monitoring.yaml file along with the main compose file:
# For Intel Xeon
docker compose -f compose.yaml -f compose.monitoring.yaml up -d
# For Intel Gaudi
docker compose -f compose.yaml -f compose.monitoring.yaml up -d
Accessing Monitoring Services¶
Once deployed with monitoring, you can access:
Prometheus:
http://${HOST_IP}:9090Grafana:
http://${HOST_IP}:3000(username:admin, password:admin)Node Exporter:
http://${HOST_IP}:9100
Benchmarking¶
Guides for evaluating the performance and accuracy of this CodeGen deployment are available:
Benchmark Type |
Guide Link |
|---|---|
Accuracy |
|
Performance |
Automated Deployment using Terraform¶
Intel® Optimized Cloud Modules for Terraform provide an automated way to deploy this CodeGen example on various Cloud Service Providers (CSPs).
Cloud Provider |
Intel Architecture |
Intel Optimized Cloud Module for Terraform |
Comments |
|---|---|---|---|
AWS |
4th Gen Intel Xeon with Intel AMX |
Available |
|
GCP |
4th/5th Gen Intel Xeon |
Available |
|
Azure |
4th/5th Gen Intel Xeon |
Work-in-progress |
Coming Soon |
Intel Tiber AI Cloud |
5th Gen Intel Xeon with Intel AMX |
Work-in-progress |
Coming Soon |
Validated Configurations¶
Deploy Method |
LLM Engine |
LLM Model |
Hardware |
|---|---|---|---|
Docker Compose |
vLLM, TGI |
Qwen/Qwen2.5-Coder-7B-Instruct |
Intel Gaudi |
Docker Compose |
vLLM, TGI |
Qwen/Qwen2.5-Coder-7B-Instruct |
Intel Xeon |
Docker Compose |
vLLM, TGI |
Qwen/Qwen2.5-Coder-7B-Instruct |
AMD EPYC |
Docker Compose |
vLLM, TGI |
Qwen/Qwen2.5-Coder-7B-Instruct |
AMD ROCm |
Helm Charts |
vLLM, TGI |
Qwen/Qwen2.5-Coder-7B-Instruct |
Intel Gaudi |
Helm Charts |
vLLM, TGI |
Qwen/Qwen2.5-Coder-7B-Instruct |
Intel Xeon |
Helm Charts |
vLLM, TGI |
Qwen/Qwen2.5-Coder-7B-Instruct |
AMD ROCm |
Contribution¶
We welcome contributions to the OPEA project. Please refer to the contribution guidelines for more information.