XTune - Model finetune tool for Intel GPU¶
Xtune is an model finetune tool for Intel GPU(Intel Arc 770)
[!NOTE]
Xtuneincorporates with Llama-Factory to offer various methods for finetuning visual models (CLIP, CnCLIP, AdaCLIP), LLM and Multi-modal models. It makes easier to choose the method and to set fine-tuning parameters.
The core features include:
Four finetune method for CLIP & CnCLIP, details in CLIP
Three finetune method for AdaCLIP, details in AdaCLIP
Automatic hyperparameter searching enabled by Optuna Optuna
Distillation from large models with Intel ARC GPU
Incorporate with Llama-Factory UI
Finetune methods for multi-modal models (to be supported)
You can use this UI to easily access basic functions(merge two tool into one UI),
or use the command line to use tools separately which is easier to customize parameters and has more comprehensive functionality.
Table of contents¶
Installation¶
[!IMPORTANT] Installation is mandatory.
Please install git first and make sure
git clonecan work.
Please fololow install_dependency to install Driver for Arc 770
1. Install xtune on native¶
Run install_xtune.sh to prepare component.
conda create -n xtune python=3.10 -y
conda activate xtune
apt install -y rsync
# open webui as default
bash prepare_xtune.sh
# this way it will not open webui
# bash prepare_xtune.sh false
Blow command is in prepare_xtune.sh. You can ignore it if you don’t want to update lib manually.
# if you want to run on NVIDIA GPU
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
# else run on A770
# You can refer to https://github.com/intel/intel-extension-for-pytorch for latest command to update lib
python -m pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/xpu
python -m pip install intel-extension-for-pytorch==2.8.10+xpu oneccl_bind_pt==2.8.0+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
2. Install xtune on docker¶
2.1 Build Docker Image¶
Build docker image with below command:
cd ../../../deployment/docker_compose
export DATA="where to find dataset"
docker build -t opea/finetuning-xtune:latest --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy --build-arg HF_TOKEN=$HF_TOKEN --build-arg DATA=$DATA -f comps/finetuning/src/Dockerfile.xtune .
2.2 Run Docker with CLI¶
Suse docker compose with below command:
export HF_TOKEN=${your_huggingface_token}
export DATA="where to find dataset"
cd ../../../deployment/docker_compose
docker compose -f compose.yaml up finetuning-xtune -d
Data Preparation¶
Please refer to data/Prepare_dataset.md for checking the details about the dataset files.
[!NOTE] Please update
dataset_info.jsonto use your custom dataset.
Prepare dataset info for caltech101
make caltech101.json in your dataset directory
[]
then make dataset_info.json in your dataset directory
{
"caltech101": {
"file_name": "caltech101.json"
},
"flickr30k": {
"file_name": "flickr30k.json"
}
}
The directory structure should look like
$DATA/
|-- caltech-101/
| |-- 101_ObjectCategories/
| | split_zhou_Caltech101.json
|-- flickr/
| |–– flickr30k-images/
| | |-- *.jpg
| |-- train_texts.jsonl
| |-- val_texts.jsonl
| |-- test_texts.jsonl
|-- dataset_info.json
|-- caltech101.json
|-- flickr30k.json
Fine-Tuning with LLaMA Board GUI (powered by Gradio)¶
[!NOTE] We don’t support multi-card in GUI now, will add it later.
When run with prepare_xtune.sh, it will automatic run ZE_AFFINITY_MASK=0 llamafactory-cli webui.
If you see “server start successfully” in terminal. You can access in web through http://localhost:7860/
The UI component information can be seen in doc/ui_component.md after run with prepare_xtune.sh.
Run with A100:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webui
Run with ARC770:
ZE_AFFINITY_MASK=0 llamafactory-cli webui
Then access in web through http://localhost:7860/
GUI using guide¶
CLIP & CnCLIP¶
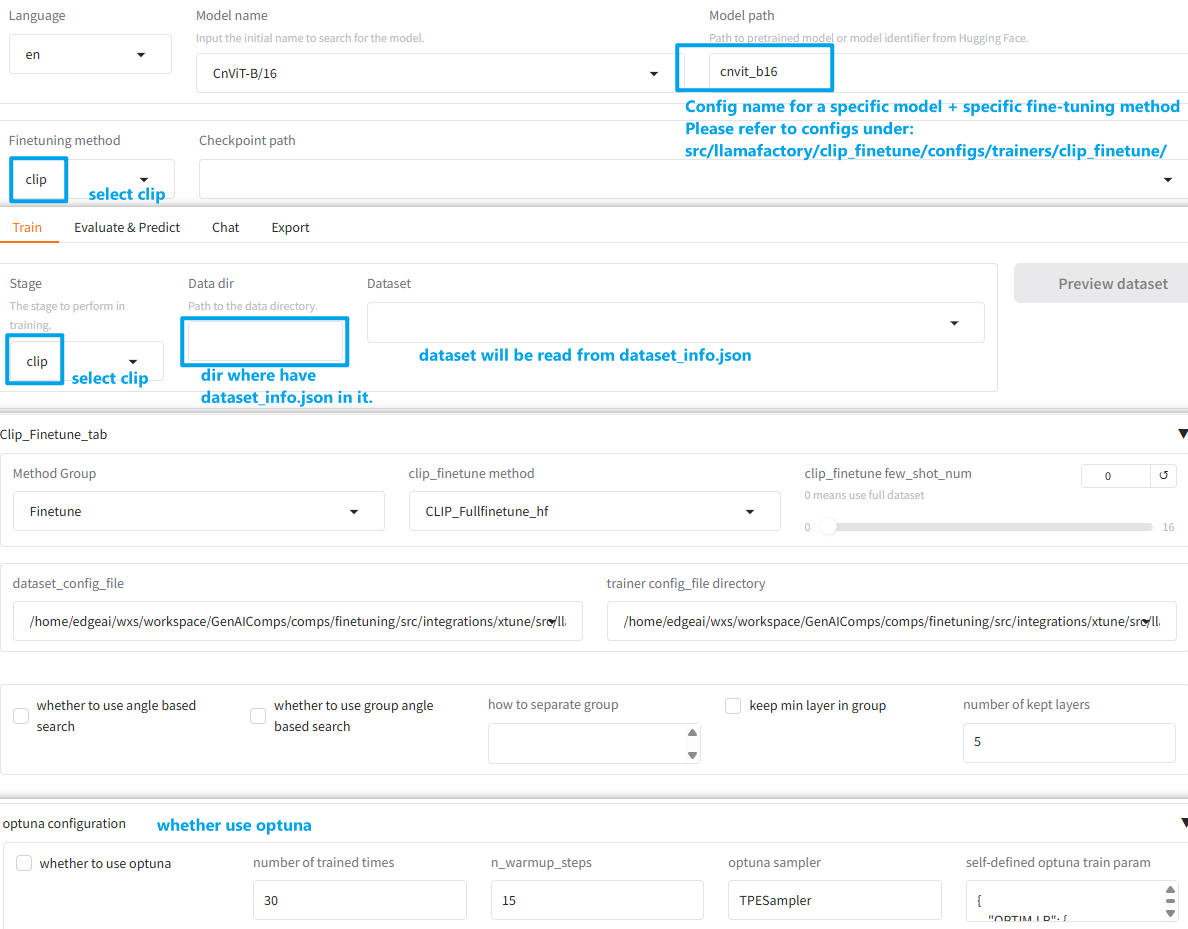
Must be set to the specified parameter values below:
Parameter
Choose Value
Model nameCnVit-B/16/CnVit-L/14/Vit-B/16/Vit-L/14Model pathMust be the detail configuration name under
src/llamafactory/clip_finetune/configs/trainers/clip_finetune/Finetuning methodclip
Stageclip
Data dirWhere you put
dataset_info.json.Method GroupFinetune
clip_finetune methodCLIP_Adapter_hf/CLIP_Bias_hf/CLIP_VPT_hf/CLIP_Fullfinetune_hf, must match withModel name(configuration name).The matching relationship between
Model name(configuration name) andclip_finetune method:clip_finetune method
Model name(configuration name)CLIP_Adapter_hf
xx_xx(e.g.,
cnvit_b16)CLIP_Bias_hf
xx_xx_bias(e.g.,
cnvit_b16_bias)CLIP_VPT_hf
xx_xx_prompt(e.g.,
cnvit_b16_prompt)CLIP_Fullfinetune_hf
xx_xx_ori(e.g.,
cnvit_b16_ori)
AdaCLIP¶
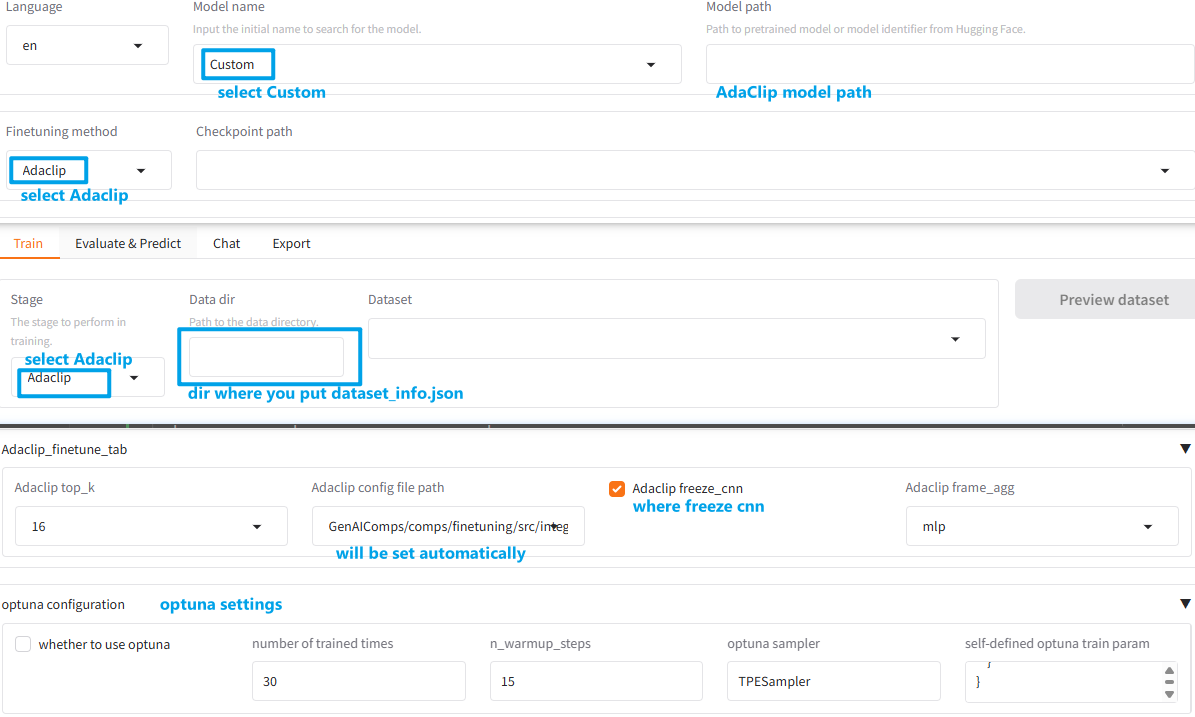
Must be set to the specified parameter values below:
Parameter
Choose Value
Model nameCustom
Model pathAdaclip model path
Finetuning methodAdaclip
StageAdaclip
Data dirWhere you put
dataset_info.json
Qwen2-VL & Qwen2.5-VL¶
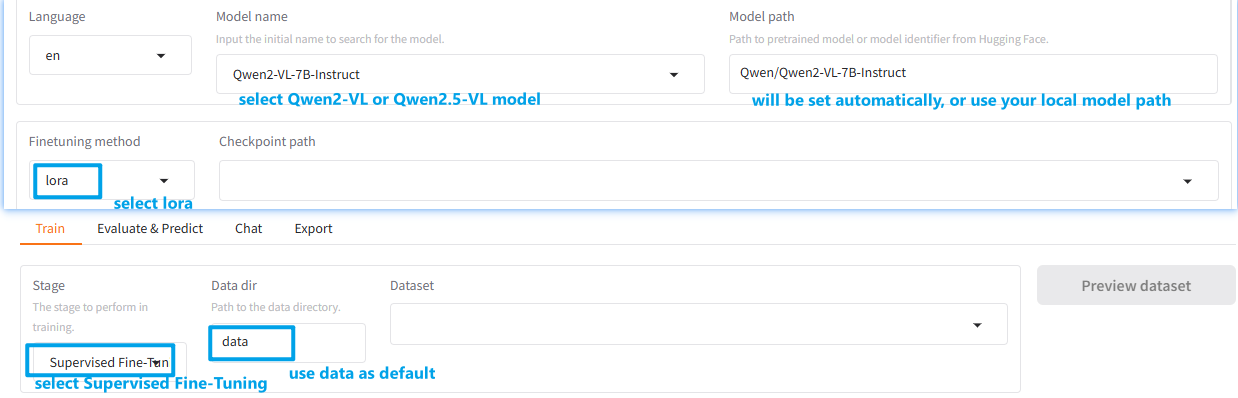
Must be set to the specified parameter values below:
Parameter
Choose Value
Model nameSelect Qwen2-VL or Qwen2.5-VL model
Model pathWill be set automatically after setting Model name, you can use your local model path,too.
Finetuning methodlora
StageSupervised Fine-Tuning
Data dirWhere you put
dataset_info.json, can usedataas default, and update your own data indata/dataset_info.json
Fine-Tuning with Shell instead of GUI¶
After run prepare_xtune.sh, it will download all related file. And open webui as default.
You can run bash prepare_xtune.sh false to close webui. Then you can run fine-tune with shell.
Below are examples.
CLIP¶
Please see doc for how to config feature
cd src/llamafactory/clip_finetune
# Please see README.md in src/llamafactory/clip_finetune for detail
CnCLIP¶
Please see doc for how to config feature
cd src/llamafactory/clip_finetune
# Please see README.md in src/llamafactory/clip_finetune for detail
AdaCLIP¶
cd src/llamafactory/adaclip_finetune
# Please see README.md in src/llamafactory/adaclip_finetune for detail
Qwen2-VL Training and Hyperparameter Optimization¶
# Please see Qwen-VL_README.md in doc to use more automated fine-tuning methods and hyperparameter tuning, bolow are simple use:
Finetune Qwen2-VL & Qwen2.5-VL with logging eval loss¶
If you want to finetune with plotting eval loss, please set eval_strategy as steps, eval_stepsand eval_dataset:
Qwen2-VL¶
export DATA='where you can find dataset_info.json'
#To point which dataset llamafactory will use, have to add the datasets into dataset_info.json before finetune.
export dataset=activitynet_qa_2000_limit_20s
export eval_dataset=activitynet_qa_val_500_limit_20s
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /model/Qwen2-VL-7B-Instruct-GPTQ-Int8 \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen2_vl \
--flash_attn auto \
--dataset_dir $DATA \
--dataset $dataset \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 20.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 10 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/Qwen2-VL-7B-Instruct-GPTQ-Int8/lora/finetune_qwen2vl \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--optim adamw_torch \
--video_fps 0.1 \
--per_device_eval_batch_size 1 \
--eval_strategy steps \
--eval_steps 100 \
--eval_dataset ${eval_dataset} \
--predict_with_generate true \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
Qwen2.5-VL¶
export DATA='where you can find dataset_info.json'
#To point which dataset llamafactory will use, have to add the datasets into dataset_info.json before finetune.
export dataset=activitynet_qa_1000_limit_20s
export eval_dataset=activitynet_qa_val_250_limit_20s
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /home/edgeai/wxs/workspace/models/Qwen2.5-VL-7B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen2_vl \
--flash_attn auto \
--dataset_dir $DATA \
--dataset $dataset \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 2 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 10 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/Qwen2.5-VL-7B-Instruct/lora/finetune_qwen2.5vl \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--optim adamw_torch \
--video_fps 0.05 \
--per_device_eval_batch_size 1 \
--eval_strategy steps \
--eval_steps 100 \
--eval_dataset $eval_dataset \
--predict_with_generate true \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
Calculation and Plotting of Evaluation Metrics During Fine-Tuning¶
If you want to plot eval metrics:
Change MODEL_NAME,EXPERIENT_NAME,EVAL_DATASET as you need and run evaluation metrics calculation sctrpt:
export MODEL_DIR = where can find eval model
export MODEL_NAME="Qwen2-VL-2B-Instruct"
export EXPERIENT_NAME="finetune_onlyplot_evalloss_5e-6"
export EVAL_DATASET=activitynet_qa_val_500_limit_20s
chmod a+x ./doc/run_eval.sh
./doc/run_eval.sh
Change model_name and experiment_name then run:
python plot_metrics.py --model_name your_model_name --experiment_name your_experiment_name
DeepSeek-R1 Distillation(not main function)¶
Please see doc for details
Step 1: Download existing CoT synthetic dataset from huggingface¶
Dataset link: https://huggingface.co/datasets/Magpie-Align/Magpie-Reasoning-V2-250K-CoT-Deepseek-R1-Llama-70B
Step 3: Register CoT dataset LLAMA-Factory dataset_info.json¶
cd data
vim dataset_info.json
# make sure the file is put under `xtune/data`
"deepseek-r1-distill-sample": {
"file_name": "Magpie-Reasoning-V2-250K-CoT-Deepseek-R1-Llama-70B-response1024.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations"
}
}
Step 4: Use the accelerate command to enable training on XPU plugin¶
accelerate config
For Single GPU:
Which type of machine are you using?
No distributed training
Do you want to run your training on CPU only (even if a GPU / Apple Silicon / Ascend NPU device is available)? [yes/NO]:NO
Do you want to use XPU plugin to speed up training on XPU? [yes/NO]:yes
Do you wish to optimize your script with torch dynamo?[yes/NO]:NO
Do you want to use DeepSpeed? [yes/NO]: NO
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:all
Would you like to enable numa efficiency? (Currently only supported on NVIDIA hardware). [yes/NO]:
Do you wish to use mixed precision?
bf16
For Multi-GPU with FSDP:
Which type of machine are you using?
multi-XPU
How many different machines will you use (use more than 1 for multi-node training)? [1]: 1
Should distributed operations be checked while running for errors? This can avoid timeout issues but will be slower. [yes/NO]: NO
Do you want to use XPU plugin to speed up training on XPU? [yes/NO]:yes
Do you wish to optimize your script with torch dynamo?[yes/NO]:NO
Do you want to use DeepSpeed? [yes/NO]: NO
Do you want to use FullyShardedDataParallel? [yes/NO]: yes
What should be your sharding strategy?
FULL_SHARD
Do you want to offload parameters and gradients to CPU? [yes/NO]: NO
What should be your auto wrap policy?
TRANSFORMER_BASED_WRAP
Do you want to use the model's `_no_split_modules` to wrap. Only applicable for Transformers [yes/NO]: yes
What should be your FSDP's backward prefetch policy?
BACKWARD_PRE
What should be your FSDP's state dict type?
SHARDED_STATE_DICT
Do you want to enable FSDP's forward prefetch policy? [yes/NO]: yes
Do you want to enable FSDP's `use_orig_params` feature? [YES/no]: yes
Do you want to enable CPU RAM efficient model loading? Only applicable for Transformers models. [YES/no]: yes
Do you want to enable FSDP activation checkpointing? [yes/NO]: yes
How many GPU(s) should be used for distributed training? [1]:2
Do you wish to use mixed precision?
bf16
Step 5: Run with train script as follows¶
export ONEAPI_DEVICE_SELECTOR="level_zero:0"
MODEL_ID="microsoft/Phi-3-mini-4k-instruct"
EXP_NAME="Phi-3-mini-4k-instruct-r1-distill-finetuned"
DATASET_NAME="deepseek-r1-distill-sample"
export OUTPUT_DIR="where to put output"
accelerate launch src/train.py --stage sft --do_train --use_fast_tokenizer --new_special_tokens "<think>,</think>" --resize_vocab --flash_attn auto --model_name_or_path ${MODEL_ID} --dataset ${DATASET_NAME} --template phi --finetuning_type lora --lora_rank 8 --lora_alpha 16 --lora_target q_proj,v_proj,k_proj,o_proj --additional_target lm_head,embed_tokens --output_dir $OUTPUT_DIR --overwrite_cache --overwrite_output_dir --warmup_steps 100 --weight_decay 0.1 --per_device_train_batch_size 1 --gradient_accumulation_steps 4 --ddp_timeout 9000 --learning_rate 5e-6 --lr_scheduler_type cosine --logging_steps 1 --save_steps 1000 --plot_loss --num_train_epochs 3 --torch_empty_cache_steps 10 --bf16
Xtune Examples¶
See screenshot of running CLIP and AdaCLIP finetune on Intel Arc A770 in README_XTUNE.md.
Citation¶
@inproceedings{zheng2024llamafactory,
title={LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models},
author={Yaowei Zheng and Richong Zhang and Junhao Zhang and Yanhan Ye and Zheyan Luo and Zhangchi Feng and Yongqiang Ma},
booktitle={Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations)},
address={Bangkok, Thailand},
publisher={Association for Computational Linguistics},
year={2024},
url={http://arxiv.org/abs/2403.13372}
}
Acknowledgement¶
This repo benefits from LLaMA-Factory, CLIP-Adapter and CoOp. Thanks for their wonderful works.