Deploy CodeGen Application on AMD GPU (ROCm) with Docker Compose¶
This README provides instructions for deploying the CodeGen application using Docker Compose on a system equipped with AMD GPUs supporting ROCm, detailing the steps to configure, run, and validate the services. This guide defaults to using the vLLM backend for LLM serving.
If the service response has a meaningful response in the value of the “choices.text” key, then we consider the vLLM service to be successfully launched
Table of Contents¶
Overview¶
This guide focuses on running the pre-configured CodeGen service using Docker Compose on AMD ROCm processing acelarating platform. It leverages containers optimized for Intel architecture for the CodeGen gateway, LLM serving (vLLM or TGI), and UI.
CodeGen Quick Start Deployment¶
This section describes how to quickly deploy and test the CodeGen service manually on an AMD GPU (ROCm) platform. The basic steps are:
Prerequisites¶
Docker and Docker Compose installed.
x86 Intel or AMD CPU.
4x AMD Instinct MI300X Accelerators.
Git installed (for cloning repository).
Hugging Face Hub API Token (for downloading models).
Access to the internet (or a private model cache).
Clone the
GenAIExamplesrepository:
git clone https://github.com/opea-project/GenAIExamples.git
cd GenAIExamples/CodeGen/docker_compose/amd/gpu/rocm/
Checkout a released version, such as v1.3:
git checkout v1.3
Available Deployment Options¶
This directory provides different Docker Compose files:
compose_vllm.yaml (vLLM - Default)¶
Description: Deploys the CodeGen application using vLLM optimized for ROCm as the backend LLM service. This is the default setup.
Services Deployed:
codegen-vllm-service,codegen-llm-server,codegen-backend-server,codegen-ui-server. Requiresset_env_vllm.sh.
compose.yaml (TGI)¶
Description: Deploys the CodeGen application using Text Generation Inference (TGI) optimized for ROCm as the backend LLM service.
Services Deployed:
codegen-tgi-service,codegen-llm-server,codegen-backend-server,codegen-ui-server. Requiresset_env.sh.
Configuration Parameters and Usage¶
Environment Variables (set_env*.sh)¶
These scripts (set_env_vllm.sh for vLLM, set_env.sh for TGI) configure crucial parameters passed to the containers.
This example covers the single-node on-premises deployment of the CodeGen example using OPEA components. There are various ways to enable CodeGen, but this example will focus on four options available for deploying the CodeGen pipeline to AMD ROCm AI Accelerators. This example begins with a Quick Start section and then documents how to modify deployments, leverage new models and configure the number of allocated devices.
This example includes the following sections:
CodeGen Quick Start Deployment: Demonstrates how to quickly deploy a CodeGen application/pipeline on AMD GPU (ROCm) platform.
CodeGen Docker Compose Files: Describes some example deployments and their docker compose files.
CodeGen Service Configuration: Describes the services and possible configuration changes.
Note This example requires access to a properly installed AMD ROCm platform with a functional Docker service configured
Generate a HuggingFace Access Token¶
Some HuggingFace resources, such as some models, are only accessible if you have an access token. If you do not already have a HuggingFace access token, you can create one by first creating an account by following the steps provided at HuggingFace and then generating a user access token.
Configure the Deployment Environment¶
Environment Variables¶
Key parameters are configured via environment variables set before running docker compose up.
Environment Variable |
Description |
Default (Set Externally) |
|---|---|---|
|
External IP address of the host machine. Required. |
|
|
Your Hugging Face Hub token for model access. Required. |
|
|
Hugging Face model ID for the CodeGen LLM (used by TGI/vLLM service). Configured within |
|
|
Hugging Face model ID for the embedding model (used by TEI service). Configured within |
|
|
Internal URL for the LLM serving endpoint (used by |
|
|
Internal URL for the Embedding service. Configured in |
|
|
Internal URL for the Data Preparation service. Configured in |
|
|
External URL for the CodeGen Gateway (MegaService). Derived from |
|
|
Internal container ports (e.g., |
N/A |
|
Network proxy settings (if required). |
|
To set up environment variables for deploying CodeGen services, source the setup_env.sh script in this directory:
For TGI
export host_ip="External_Public_IP" #ip address of the node
export HF_TOKEN="Your_Huggingface_API_Token"
export http_proxy="Your_HTTP_Proxy" #http proxy if any
export https_proxy="Your_HTTPs_Proxy" #https proxy if any
export no_proxy=localhost,127.0.0.1,$host_ip #additional no proxies if needed
export no_proxy=$no_proxy
source ./set_env.sh
For vLLM
export host_ip="External_Public_IP" #ip address of the node
export HF_TOKEN="Your_Huggingface_API_Token"
export http_proxy="Your_HTTP_Proxy" #http proxy if any
export https_proxy="Your_HTTPs_Proxy" #https proxy if any
export no_proxy=localhost,127.0.0.1,$host_ip #additional no proxies if needed
export no_proxy=$no_proxy
source ./set_env_vllm.sh
Docker Compose GPU Configuration¶
To enable GPU support for AMD GPUs, the following configuration is added to the Docker Compose files (compose.yaml, compose_vllm.yaml) for the LLM serving container:
# Example for vLLM service in compose_vllm.yaml
# Note: Modern docker compose might use deploy.resources syntax instead.
# Check your docker version and compose file.
shm_size: 1g
devices:
- /dev/kfd:/dev/kfd
- /dev/dri/:/dev/dri/
cap_add:
- SYS_PTRACE
group_add:
- video
security_opt:
- seccomp:unconfined
This configuration forwards all available GPUs to the container. To use a specific GPU, specify its cardN and renderN device IDs (e.g., /dev/dri/card0:/dev/dri/card0, /dev/dri/render128:/dev/dri/render128). For example:
shm_size: 1g
devices:
- /dev/kfd:/dev/kfd
- /dev/dri/card0:/dev/dri/card0
- /dev/dri/render128:/dev/dri/render128
cap_add:
- SYS_PTRACE
group_add:
- video
security_opt:
- seccomp:unconfined
How to Identify GPU Device IDs:
Use AMD GPU driver utilities to determine the correct cardN and renderN IDs for your GPU.
Deploy the Services Using Docker Compose¶
Please refer to the table below to build different microservices from source:
When using the default compose_vllm.yaml (vLLM-based), the following services are deployed:
Service Name |
Default Port (Host) |
Internal Port |
Purpose |
|---|---|---|---|
codegen-vllm-service |
|
8000 |
LLM Serving (vLLM on ROCm) |
codegen-llm-server |
|
80 |
LLM Microservice Wrapper |
codegen-backend-server |
|
80 |
CodeGen MegaService/Gateway |
codegen-ui-server |
|
80 |
Frontend User Interface |
To deploy the CodeGen services, execute the docker compose up command with the appropriate arguments. For a vLLM deployment, execute:
docker compose -f compose_vllm.sh up -d
The CodeGen docker images should automatically be downloaded from the OPEA registry and deployed on the AMD GPU (ROCM) Platform:
[+] Running 5/5_default Created 0.3s
✔ Network rocm_default Created 0.3s
✔ Container codegen-vllm-service Healthy 100.9s
✔ Container codegen-llm-server Started 101.2s
✔ Container codegen-backend-server Started 101.5s
✔ Container codegen-ui-server Started 101.9s
To deploy the CodeGen services, execute the docker compose up command with the appropriate arguments. For a TGI deployment, execute:¶
docker compose up -d
The CodeGen docker images should automatically be downloaded from the OPEA registry and deployed on the AMD GPU (ROCM) Platform:
[+] Running 5/5_default Created 0.4s
✔ Network rocm_default Created 0.4s
✔ Container codegen-tgi-service Healthy 102.6s
✔ Container codegen-llm-server Started 100.2s
✔ Container codegen-backend-server Started 103.7s
✔ Container codegen-ui-server Started 102.9s
Building Custom Images (Optional)¶
If you need to modify the microservices:
Clone the OPEA GenAIComps repository.
Follow build instructions in the respective component directories (e.g.,
comps/llms/text-generation,comps/codegen,comps/ui/gradio, etc.). Use the provided Dockerfiles (e.g.,CodeGen/Dockerfile,CodeGen/ui/docker/Dockerfile.gradio).Tag your custom images appropriately (e.g.,
my-custom-codegen:latest).Update the
image:fields in thecompose.yamlfile to use your custom image tags.
Refer to the main CodeGen README for links to relevant GenAIComps components.
Validate Services¶
Check the Deployment Status for TGI base deployment¶
After running docker compose, check if all the containers launched via docker compose have started:
docker ps -a
For the default deployment, the following 10 containers should have started:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1d08caeae2ed opea/codegen-ui:latest "docker-entrypoint.s…" 2 minutes ago Up About a minute 0.0.0.0:18151->5173/tcp, [::]:18151->5173/tcp codegen-ui-server
f52adc66c116 opea/codegen:latest "python codegen.py" 2 minutes ago Up About a minute 0.0.0.0:18150->7778/tcp, [::]:18150->7778/tcp codegen-backend-server
4b1cb8f5d4ff opea/llm-textgen:latest "bash entrypoint.sh" 2 minutes ago Up About a minute 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp codegen-llm-server
3bb4ee0abf15 ghcr.io/huggingface/text-generation-inference:2.4.1-rocm "/tgi-entrypoint.sh …" 2 minutes ago Up 2 minutes (healthy) 0.0.0.0:8028->80/tcp, [::]:8028->80/tcp codegen-tgi-service
Check the Deployment Status for vLLM base deployment¶
After running docker compose, check if all the containers launched via docker compose have started:
docker ps -a
For the default deployment, the following 10 containers should have started:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f100cc326343 opea/codegen-ui:latest "docker-entrypoint.s…" 16 minutes ago Up 14 minutes 0.0.0.0:18151->5173/tcp, [::]:18151->5173/tcp codegen-ui-server
c59de0b2da5b opea/codegen:latest "python codegen.py" 16 minutes ago Up 14 minutes 0.0.0.0:18150->7778/tcp, [::]:18150->7778/tcp codegen-backend-server
dcd83e0e4c0f opea/llm-textgen:latest "bash entrypoint.sh" 16 minutes ago Up 14 minutes 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp codegen-llm-server
d091d8f2fab6 opea/vllm-rocm:latest "python3 /workspace/…" 16 minutes ago Up 16 minutes (healthy) 0.0.0.0:8028->8011/tcp, [::]:8028->8011/tcp codegen-vllm-service
Test the Pipeline¶
If you use vLLM:¶
DATA='{"model": "Qwen/Qwen2.5-Coder-7B-Instruct", '\
'"messages": [{"role": "user", "content": "Implement a high-level API for a TODO list application. '\
'The API takes as input an operation request and updates the TODO list in place. '\
'If the request is invalid, raise an exception."}], "max_tokens": 256}'
curl http://${HOST_IP}:${CODEGEN_VLLM_SERVICE_PORT}/v1/chat/completions \
-X POST \
-d "$DATA" \
-H 'Content-Type: application/json'
Checking the response from the service. The response should be similar to JSON:
{
"id": "chatcmpl-142f34ef35b64a8db3deedd170fed951",
"object": "chat.completion",
"created": 1742270316,
"model": "Qwen/Qwen2.5-Coder-7B-Instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "```python\nfrom typing import Optional, List, Dict, Union\nfrom pydantic import BaseModel, validator\n\nclass OperationRequest(BaseModel):\n # Assuming OperationRequest is already defined as per the given text\n pass\n\nclass UpdateOperation(OperationRequest):\n new_items: List[str]\n\n def apply_and_maybe_raise(self, updatable_item: \"Updatable todo list\") -> None:\n # Assuming updatable_item is an instance of Updatable todo list\n self.validate()\n updatable_item.add_items(self.new_items)\n\nclass Updatable:\n # Abstract class for items that can be updated\n pass\n\nclass TodoList(Updatable):\n # Class that represents a todo list\n items: List[str]\n\n def add_items(self, new_items: List[str]) -> None:\n self.items.extend(new_items)\n\ndef handle_request(operation_request: OperationRequest) -> None:\n # Function to handle an operation request\n if isinstance(operation_request, UpdateOperation):\n operation_request.apply_and_maybe_raise(get_todo_list_for_update())\n else:\n raise ValueError(\"Invalid operation request\")\n\ndef get_todo_list_for_update() -> TodoList:\n # Function to get the todo list for update\n # Assuming this function returns the",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "length",
"stop_reason": null
}
],
"usage": { "prompt_tokens": 66, "total_tokens": 322, "completion_tokens": 256, "prompt_tokens_details": null },
"prompt_logprobs": null
}
If the service response has a meaningful response in the value of the “choices.message.content” key, then we consider the vLLM service to be successfully launched
If you use TGI:¶
DATA='{"inputs":"Implement a high-level API for a TODO list application. '\
'The API takes as input an operation request and updates the TODO list in place. '\
'If the request is invalid, raise an exception.",'\
'"parameters":{"max_new_tokens":256,"do_sample": true}}'
curl http://${HOST_IP}:${CODEGEN_TGI_SERVICE_PORT}/generate \
-X POST \
-d "$DATA" \
-H 'Content-Type: application/json'
Checking the response from the service. The response should be similar to JSON:
{
"generated_text": " The supported operations are \"add_task\", \"complete_task\", and \"remove_task\". Each operation can be defined with a corresponding function in the API.\n\nAdd your API in the following format:\n\n```\nTODO App API\n\nsupported operations:\n\noperation name description\n----------------------- ------------------------------------------------\n<operation_name> <operation description>\n```\n\nUse type hints for function parameters and return values. Specify a text description of the API's supported operations.\n\nUse the following code snippet as a starting point for your high-level API function:\n\n```\nclass TodoAPI:\n def __init__(self, tasks: List[str]):\n self.tasks = tasks # List of tasks to manage\n\n def add_task(self, task: str) -> None:\n self.tasks.append(task)\n\n def complete_task(self, task: str) -> None:\n self.tasks = [t for t in self.tasks if t != task]\n\n def remove_task(self, task: str) -> None:\n self.tasks = [t for t in self.tasks if t != task]\n\n def handle_request(self, request: Dict[str, str]) -> None:\n operation = request.get('operation')\n if operation == 'add_task':\n self.add_task(request.get('task'))\n elif"
}
If the service response has a meaningful response in the value of the “generated_text” key, then we consider the TGI service to be successfully launched
2. Validate the LLM Service¶
DATA='{"query":"Implement a high-level API for a TODO list application. '\
'The API takes as input an operation request and updates the TODO list in place. '\
'If the request is invalid, raise an exception.",'\
'"max_tokens":256,"top_k":10,"top_p":0.95,"typical_p":0.95,"temperature":0.01,'\
'"repetition_penalty":1.03,"stream":false}'
curl http://${HOST_IP}:${CODEGEN_LLM_SERVICE_PORT}/v1/chat/completions \
-X POST \
-d "$DATA" \
-H 'Content-Type: application/json'
Checking the response from the service. The response should be similar to JSON:
{
"id": "cmpl-4e89a590b1af46bfb37ce8f12b2996f8",
"choices": [
{
"finish_reason": "length",
"index": 0,
"logprobs": null,
"text": " The API should support the following operations:\n\n1. Add a new task to the TODO list.\n2. Remove a task from the TODO list.\n3. Mark a task as completed.\n4. Retrieve the list of all tasks.\n\nThe API should also support the following features:\n\n1. The ability to filter tasks based on their completion status.\n2. The ability to sort tasks based on their priority.\n3. The ability to search for tasks based on their description.\n\nHere is an example of how the API can be used:\n\n```python\ntodo_list = []\napi = TodoListAPI(todo_list)\n\n# Add tasks\napi.add_task(\"Buy groceries\")\napi.add_task(\"Finish homework\")\n\n# Mark a task as completed\napi.mark_task_completed(\"Buy groceries\")\n\n# Retrieve the list of all tasks\nprint(api.get_all_tasks())\n\n# Filter tasks based on completion status\nprint(api.filter_tasks(completed=True))\n\n# Sort tasks based on priority\napi.sort_tasks(priority=\"high\")\n\n# Search for tasks based on description\nprint(api.search_tasks(description=\"homework\"))\n```\n\nIn this example, the `TodoListAPI` class is used to manage the TODO list. The `add_task` method adds a new task to the list, the `mark_task_completed` method",
"stop_reason": null,
"prompt_logprobs": null
}
],
"created": 1742270567,
"model": "Qwen/Qwen2.5-Coder-7B-Instruct",
"object": "text_completion",
"system_fingerprint": null,
"usage": {
"completion_tokens": 256,
"prompt_tokens": 37,
"total_tokens": 293,
"completion_tokens_details": null,
"prompt_tokens_details": null
}
}
Accessing the User Interface (UI)¶
Multiple UI options can be configured via the compose.yaml.
Svelte UI (Optional)¶
Modify
compose.yaml: Comment out thecodegen-gradio-ui-serverservice and uncomment/add thecodegen-xeon-ui-server(Svelte) service definition, ensuring the port mapping is correct (e.g.,"- 5173:5173").Restart Docker Compose:
docker compose --profile <profile_name> up -dAccess:
http://{HOST_IP}:5173(or the host port you mapped).
VS Code Extension (Optional)¶
Users can interact with the backend service using the Neural Copilot VS Code extension.
Install: Find and install
Neural Copilotfrom the VS Code Marketplace.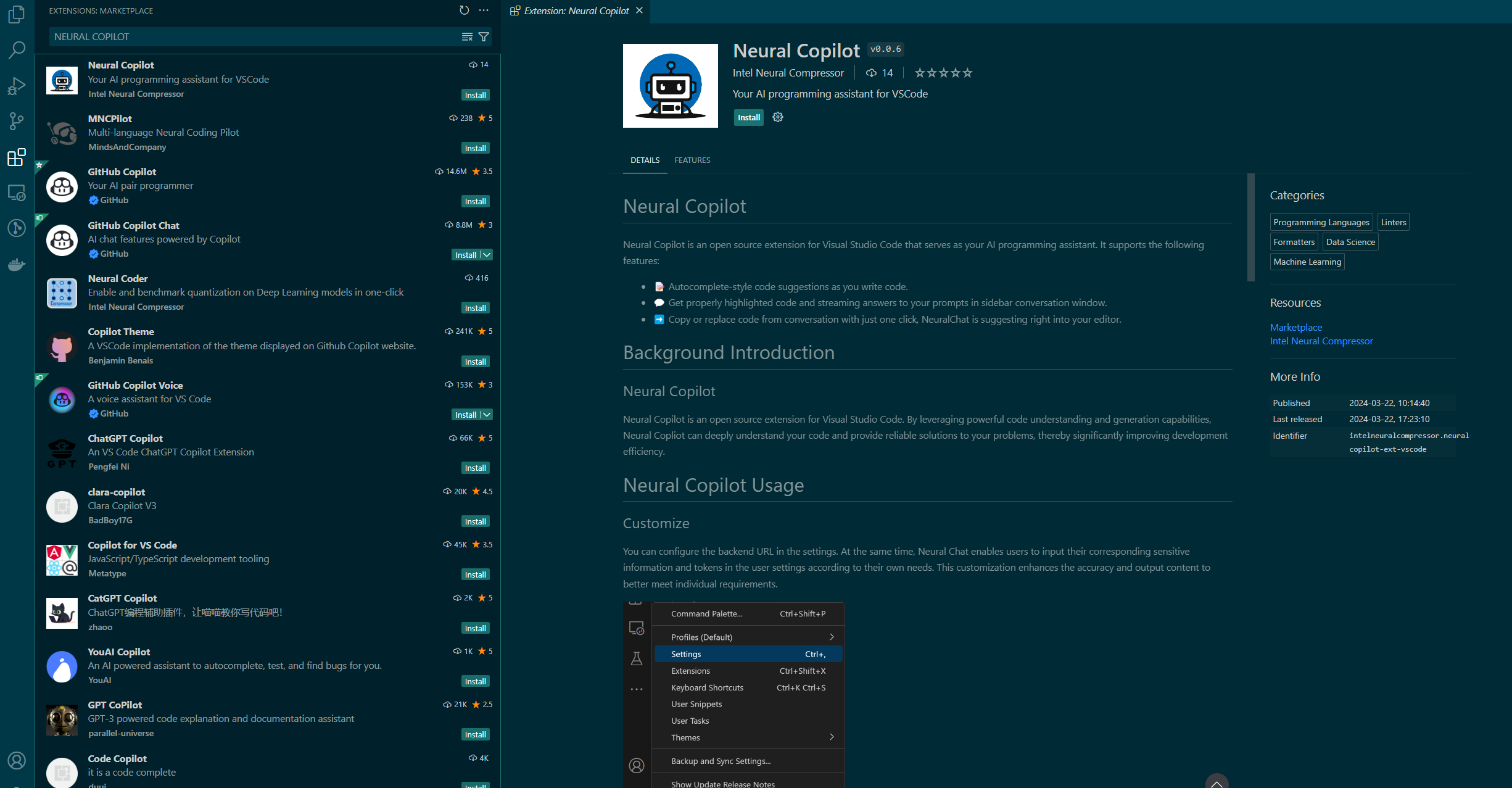
Configure: Set the “Service URL” in the extension settings to your CodeGen backend endpoint:
http://${HOST_IP}:7778/v1/codegen(use the correct port if changed).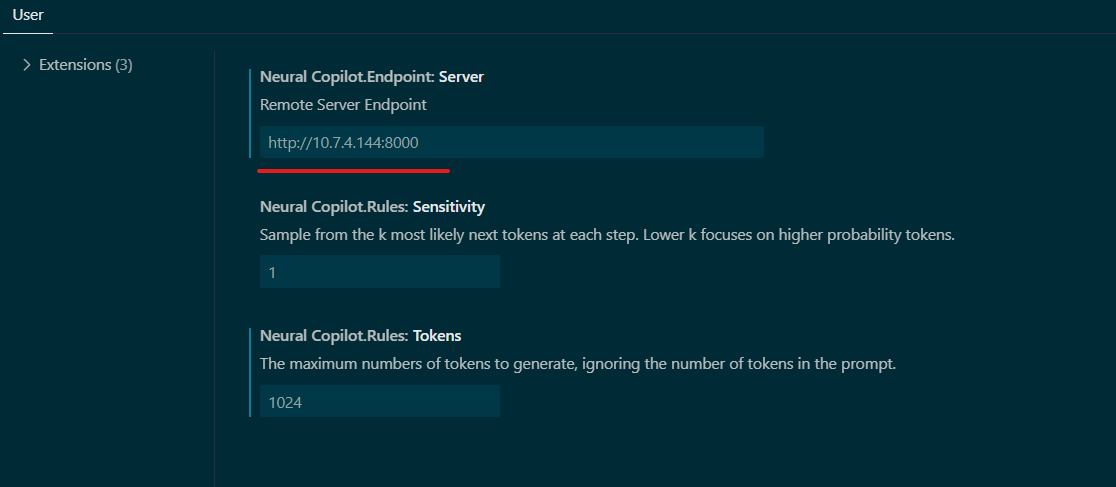
Usage:
Inline Suggestion: Type a comment describing the code you want (e.g.,
# Python function to read a file) and wait for suggestions.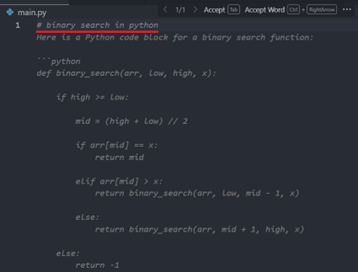
Chat: Use the Neural Copilot panel to chat with the AI assistant about code.
Troubleshooting¶
Model Download Issues: Check
HF_TOKEN. Ensure internet connectivity or correct proxy settings. Check logs oftgi-service/vllm-serviceandtei-embedding-server. Gated models need prior Hugging Face access.Connection Errors: Verify
HOST_IPis correct and accessible. Checkdocker psfor port mappings. Ensureno_proxyincludesHOST_IPif using a proxy. Check logs of the service failing to connect (e.g.,codegen-backend-serverlogs if it can’t reachcodegen-llm-server).“Container name is in use”: Stop existing containers (
docker compose down) or changecontainer_nameincompose.yaml.Resource Issues: CodeGen models can be memory-intensive. Monitor host RAM usage. Increase Docker resources if needed.
Cleanup the Deployment¶
To stop the containers associated with the deployment, execute the following command:
docker compose -f compose.yaml down
[+] Running 0/1
[+] Running 1/2degen-ui-server Stopping 0.4s
[+] Running 2/3degen-ui-server Removed 10.5s
[+] Running 2/3degen-ui-server Removed 10.5s
[+] Running 3/4degen-ui-server Removed 10.5s
[+] Running 5/5degen-ui-server Removed 10.5s
✔ Container codegen-ui-server Removed 10.5s
✔ Container codegen-backend-server Removed 10.4s
✔ Container codegen-llm-server Removed 10.4s
✔ Container codegen-tgi-service Removed 8.0s
✔ Network rocm_default Removed 0.6s
compose.yaml - TGI Deployment¶
The TGI (Text Generation Inference) deployment and the default deployment differ primarily in their service configurations and specific focus on handling large language models (LLMs). The TGI deployment includes a unique codegen-tgi-service, which utilizes the ghcr.io/huggingface/text-generation-inference:2.4.1-rocm image and is specifically configured to run on AMD hardware.
Service Name |
Image Name |
AMD Use |
|---|---|---|
codegen-backend-server |
opea/codegen:latest |
no |
codegen-llm-server |
opea/codegen:latest |
no |
codegen-tgi-service |
ghcr.io/huggingface/text-generation-inference:2.4.1-rocm |
yes |
codegen-ui-server |
opea/codegen-ui:latest |
no |
compose_vllm.yaml - vLLM Deployment¶
The vLLM deployment utilizes AMD devices primarily for the vllm-service, which handles large language model (LLM) tasks. This service is configured to maximize the use of AMD’s capabilities, potentially allocating multiple devices to enhance parallel processing and throughput.
Service Name |
Image Name |
AMD Use |
|---|---|---|
codegen-backend-server |
opea/codegen:latest |
no |
codegen-llm-server |
opea/codegen:latest |
no |
codegen-vllm-service |
opea/vllm-rocm:latest |
yes |
codegen-ui-server |
opea/codegen-ui:latest |
no |
CodeGen Service Configuration¶
The table provides a comprehensive overview of the CodeGen services utilized across various deployments as illustrated in the example Docker Compose files. Each row in the table represents a distinct service, detailing its possible images used to enable it and a concise description of its function within the deployment architecture. These services collectively enable functionalities such as data storage and management, text embedding, retrieval, reranking, and large language model processing.
ex.: (From ChatQna) | Service Name | Possible Image Names | Optional | Description | redis-vector-db | redis/redis-stack:7.2.0-v9 | No | Acts as a Redis database for storing and managing
Conclusion¶
In the configuration of the vllm-service and the tgi-service, two variables play a primary role in determining the service’s performance and functionality. The LLM_MODEL_ID parameter specifies the particular large language model (LLM) that the service will utilize, effectively determining the capabilities and characteristics of the language processing tasks it can perform. This model identifier ensures that the service is aligned with the specific requirements of the application, whether it involves text generation, comprehension, or other language-related tasks.
However, developers need to be aware of the models that have been tested with the respective service image supporting the vllm-service and tgi-service. For example, documentation for the OPEA GenAIComps v1.3 release specify the list of validated LLM models for each AMD ROCm enabled service image. Specific models may have stringent requirements on the number of AMD ROCm devices required to support them.
This guide should enable developer to deploy the default configuration or any of the other compose yaml files for different configurations. It also highlights the configurable parameters that can be set before deployment.
Next Steps¶
Consult the OPEA GenAIComps repository for details on individual microservices.
Refer to the main CodeGen README for links to benchmarking and Kubernetes deployment options.