Deploying SearchQnA on AMD ROCm Platform¶
This document outlines the single node deployment process for a SearchQnA application utilizing the GenAIComps microservices on AMD ROCm Platform.
Table of Contents¶
Launch the UI: Guideline for UI usage
SearchQnA Quick Start Deployment¶
This section describes how to quickly deploy and test the SearchQnA service manually on an AMD ROCm Platform. The basic steps are:
Access the Code¶
Clone the GenAIExample repository and access the SearchQnA AMD ROCm Platform Docker Compose files and supporting scripts:
git clone https://github.com/opea-project/GenAIExamples.git
cd GenAIExamples/SearchQnA/docker_compose/amd/gpu/rocm
Checkout a released version, such as v1.3:
git checkout v1.3
Generate a HuggingFace Access Token¶
Some HuggingFace resources require an access token. Developers can create one by first signing up on HuggingFace and then generating a user access token.
Configure the Deployment Environment¶
To set up environment variables for deploying SearchQnA services, set up some parameters specific to the deployment environment and source the set_env.sh script in this directory:
For vLLM inference type deployment (default)¶
export host_ip="External_Public_IP" # ip address of the node
export GOOGLE_CSE_ID="your cse id"
export GOOGLE_API_KEY="your google api key"
export HF_TOKEN="Your_HuggingFace_API_Token"
export http_proxy="Your_HTTP_Proxy" # http proxy if any
export https_proxy="Your_HTTPs_Proxy" # https proxy if any
export no_proxy=localhost,127.0.0.1,$host_ip # additional no proxies if needed
export NGINX_PORT=${your_nginx_port} # your usable port for nginx, 80 for example
source ./set_env_vllm.sh
For TGI inference type deployment¶
export host_ip="External_Public_IP" # ip address of the node
export GOOGLE_CSE_ID="your cse id"
export GOOGLE_API_KEY="your google api key"
export HF_TOKEN="Your_HuggingFace_API_Token"
export http_proxy="Your_HTTP_Proxy" # http proxy if any
export https_proxy="Your_HTTPs_Proxy" # https proxy if any
export no_proxy=localhost,127.0.0.1,$host_ip # additional no proxies if needed
export NGINX_PORT=${your_nginx_port} # your usable port for nginx, 80 for example
source ./set_env.sh
Consult the section on SearchQnA Service configuration for information on how service specific configuration parameters affect deployments.
Deploy the Services Using Docker Compose¶
To deploy the SearchQnA services, execute the docker compose up command with the appropriate arguments. For a default deployment, execute:
For vLLM inference type deployment (default)¶
//with VLLM:
docker compose -f compose_vllm.yaml up -d
For TGI inference type deployment¶
//with TGI:
docker compose -f compose.yaml up -d
Note: developers should build docker image from source when:
Developing off the git main branch (as the container’s ports in the repo may be different from the published docker image).
Unable to download the docker image.
Use a specific version of Docker image.
Please refer to the table below to build different microservices from source:
Microservice |
Deployment Guide |
|---|---|
Reranking |
|
vLLM |
|
LLM-TextGen |
|
Web-Retriever |
|
Embedding |
|
MegaService |
|
UI |
Check the Deployment Status¶
After running Docker Compose, the list of images can be checked using the following command:
docker ps -a
For the default deployment, the following containers should have started
For vLLM inference type deployment (default)¶
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
50e5f4a00fcc opea/searchqna-ui:latest "docker-entrypoint.s…" About a minute ago Up About a minute 0.0.0.0:18143->5173/tcp, [::]:18143->5173/tcp search-ui-server
a8f030d17e40 opea/searchqna:latest "python searchqna.py" About a minute ago Up About a minute 0.0.0.0:18142->8888/tcp, [::]:18142->8888/tcp search-backend-server
916c5db048a2 opea/llm-textgen:latest "bash entrypoint.sh" About a minute ago Up About a minute 0.0.0.0:3007->9000/tcp, [::]:3007->9000/tcp search-llm-server
bb46cdaf1794 opea/reranking:latest "python opea_reranki…" About a minute ago Up About a minute 0.0.0.0:3005->8000/tcp, [::]:3005->8000/tcp search-reranking-server
d89ab0ef3f41 opea/embedding:latest "sh -c 'python $( [ …" About a minute ago Up About a minute 0.0.0.0:3002->6000/tcp, [::]:3002->6000/tcp search-embedding-server
b248e55dd20f opea/vllm-rocm:latest "python3 /workspace/…" About a minute ago Up About a minute 0.0.0.0:3080->8011/tcp, [::]:3080->8011/tcp search-vllm-service
c3800753fac5 opea/web-retriever:latest "python opea_web_ret…" About a minute ago Up About a minute 0.0.0.0:3003->7077/tcp, [::]:3003->7077/tcp search-web-retriever-server
0db8af486bd0 ghcr.io/huggingface/text-embeddings-inference:cpu-1.7 "text-embeddings-rou…" About a minute ago Up About a minute 0.0.0.0:3001->80/tcp, [::]:3001->80/tcp search-tei-embedding-server
3125915447ef ghcr.io/huggingface/text-embeddings-inference:cpu-1.7 "text-embeddings-rou…" About a minute ago Up About a minute 0.0.0.0:3004->80/tcp, [::]:3004->80/tcp search-tei-reranking-server
For TGI inference type deployment¶
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
67cc886949a3 opea/searchqna-ui:latest "docker-entrypoint.s…" About a minute ago Up About a minute 0.0.0.0:18143->5173/tcp, [::]:18143->5173/tcp search-ui-server
6547aca0d5fd opea/searchqna:latest "python searchqna.py" About a minute ago Up About a minute 0.0.0.0:18142->8888/tcp, [::]:18142->8888/tcp search-backend-server
213b5d4d5fa5 opea/embedding:latest "sh -c 'python $( [ …" About a minute ago Up About a minute 0.0.0.0:3002->6000/tcp, [::]:3002->6000/tcp search-embedding-server
6b90d16100b2 opea/reranking:latest "python opea_reranki…" About a minute ago Up About a minute 0.0.0.0:3005->8000/tcp, [::]:3005->8000/tcp search-reranking-server
3266fd85207e opea/llm-textgen:latest "bash entrypoint.sh" About a minute ago Up About a minute 0.0.0.0:3007->9000/tcp, [::]:3007->9000/tcp search-llm-server
d7322b70c15d ghcr.io/huggingface/text-generation-inference:2.4.1-rocm "/tgi-entrypoint.sh …" About a minute ago Up About a minute 0.0.0.0:3006->80/tcp, [::]:3006->80/tcp search-tgi-service
a703b91b28ed ghcr.io/huggingface/text-embeddings-inference:cpu-1.6 "text-embeddings-rou…" About a minute ago Up About a minute 0.0.0.0:3001->80/tcp, [::]:3001->80/tcp search-tei-embedding-server
22098a5eaf59 ghcr.io/huggingface/text-embeddings-inference:cpu-1.6 "text-embeddings-rou…" About a minute ago Up About a minute 0.0.0.0:3004->80/tcp, [::]:3004->80/tcp search-tei-reranking-server
830fe84c971d opea/web-retriever:latest "python opea_web_ret…" About a minute ago Up About a minute 0.0.0.0:3003->7077/tcp, [::]:3003->7077/tcp search-web-retriever-server
If any issues are encountered during deployment, refer to the Troubleshooting section.
Validate the Pipeline¶
Once the SearchQnA services are running, test the pipeline using the following command:
DATA='{"messages": "What is the latest news from the AI world? '\
'Give me a summary.","stream": "True"}'
curl http://${host_ip}:3008/v1/searchqna \
-H "Content-Type: application/json" \
-d "$DATA"
Note The value of host_ip was set using the set_env.sh script and can be found in the .env file.
Checking the response from the service. The response should be similar to JSON:
data: {"id":"cmpl-f095893d094a4e9989423c2364f00bc1","choices":[{"finish_reason":null,"index":0,"logprobs":null,"text":",","stop_reason":null}],"created":1742960360,"model":"Intel/neural-chat-7b-v3-3","object":"text_completion","system_fingerprint":null,"usage":null}
data: {"id":"cmpl-f095893d094a4e9989423c2364f00bc1","choices":[{"finish_reason":null,"index":0,"logprobs":null,"text":" with","stop_reason":null}],"created":1742960360,"model":"Intel/neural-chat-7b-v3-3","object":"text_completion","system_fingerprint":null,"usage":null}
data: {"id":"cmpl-f095893d094a4e9989423c2364f00bc1","choices":[{"finish_reason":null,"index":0,"logprobs":null,"text":" calls","stop_reason":null}],"created":1742960360,"model":"Intel/neural-chat-7b-v3-3","object":"text_completion","system_fingerprint":null,"usage":null}
data: {"id":"cmpl-f095893d094a4e9989423c2364f00bc1","choices":[{"finish_reason":null,"index":0,"logprobs":null,"text":" for","stop_reason":null}],"created":1742960360,"model":"Intel/neural-chat-7b-v3-3","object":"text_completion","system_fingerprint":null,"usage":null}
data: {"id":"cmpl-f095893d094a4e9989423c2364f00bc1","choices":[{"finish_reason":null,"index":0,"logprobs":null,"text":" more","stop_reason":null}],"created":1742960360,"model":"Intel/neural-chat-7b-v3-3","object":"text_completion","system_fingerprint":null,"usage":null}
data: {"id":"cmpl-f095893d094a4e9989423c2364f00bc1","choices":[{"finish_reason":null,"index":0,"logprobs":null,"text":" regulation","stop_reason":null}],"created":1742960360,"model":"Intel/neural-chat-7b-v3-3","object":"text_completion","system_fingerprint":null,"usage":null}
data: {"id":"cmpl-f095893d094a4e9989423c2364f00bc1","choices":[{"finish_reason":null,"index":0,"logprobs":null,"text":" and","stop_reason":null}],"created":1742960360,"model":"Intel/neural-chat-7b-v3-3","object":"text_completion","system_fingerprint":null,"usage":null}
data: {"id":"cmpl-f095893d094a4e9989423c2364f00bc1","choices":[{"finish_reason":null,"index":0,"logprobs":null,"text":" trans","stop_reason":null}],"created":1742960360,"model":"Intel/neural-chat-7b-v3-3","object":"text_completion","system_fingerprint":null,"usage":null}
data: {"id":"cmpl-f095893d094a4e9989423c2364f00bc1","choices":[{"finish_reason":null,"index":0,"logprobs":null,"text":"parency","stop_reason":null}],"created":1742960360,"model":"Intel/neural-chat-7b-v3-3","object":"text_completion","system_fingerprint":null,"usage":null}
data: {"id":"cmpl-f095893d094a4e9989423c2364f00bc1","choices":[{"finish_reason":null,"index":0,"logprobs":null,"text":".","stop_reason":null}],"created":1742960360,"model":"Intel/neural-chat-7b-v3-3","object":"text_completion","system_fingerprint":null,"usage":null}
data: {"id":"cmpl-f095893d094a4e9989423c2364f00bc1","choices":[{"finish_reason":"stop","index":0,"logprobs":null,"text":"","stop_reason":null}],"created":1742960360,"model":"Intel/neural-chat-7b-v3-3","object":"text_completion","system_fingerprint":null,"usage":null}
data: [DONE]
A response text similar to the one above indicates that the service verification was successful.
Note : Access the SearchQnA UI by web browser through this URL: http://${host_ip}:80. Please confirm the 80 port is opened in the firewall. To validate each microservice used in the pipeline refer to the Validate Microservices section.
Cleanup the Deployment¶
To stop the containers associated with the deployment, execute the following command:
For vLLM inference type deployment (default)¶
//with VLLM:
docker compose -f compose_vllm.yaml down
For TGI inference type deployment¶
//with TGI:
docker compose -f compose.yaml down
All the SearchQnA containers will be stopped and then removed on completion of the “down” command.
SearchQnA Docker Compose Files¶
When deploying a SearchQnA pipeline on an AMD GPUs (ROCm), different large language model serving frameworks can be selected. The table below outlines the available configurations included in the application. These configurations can serve as templates and be extended to other components available in GenAIComps.
File |
Description |
|---|---|
Default compose file using tgi as serving framework |
|
The LLM serving framework is vLLM. All other configurations remain the same as the default |
Validate Microservices¶
Embedding backend Service
curl http://${host_ip}:3001/embed \ -X POST \ -d '{"inputs":"What is Deep Learning?"}' \ -H 'Content-Type: application/json'
Embedding Microservice
curl http://${host_ip}:3002/v1/embeddings\ -X POST \ -d '{"text":"hello"}' \ -H 'Content-Type: application/json'
Web Retriever Microservice
export your_embedding=$(python3 -c "import random; embedding = [random.uniform(-1, 1) for _ in range(768)]; print(embedding)") curl http://${host_ip}:3003/v1/web_retrieval \ -X POST \ -d "{\"text\":\"What is the 2024 holiday schedule?\",\"embedding\":${your_embedding}}" \ -H 'Content-Type: application/json'
Reranking backend Service
# TEI Reranking service
curl http://${host_ip}:3004/rerank \
-X POST \
-d '{"query":"What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]}' \
-H 'Content-Type: application/json'
Reranking Microservice
curl http://${host_ip}:3005/v1/reranking\
-X POST \
-d '{"initial_query":"What is Deep Learning?", "retrieved_docs": [{"text":"Deep Learning is not..."}, {"text":"Deep learning is..."}]}' \
-H 'Content-Type: application/json'
LLM backend Service
# TGI service
curl http://${host_ip}:3006/generate \
-X POST \
-d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":17, "do_sample": true}}' \
-H 'Content-Type: application/json'
LLM Microservice
curl http://${host_ip}:3007/v1/chat/completions\ -X POST \ -d '{"query":"What is Deep Learning?","max_tokens":17,"top_k":10,"top_p":0.95,"typical_p":0.95,"temperature":0.01,"repetition_penalty":1.03,"stream":true}' \ -H 'Content-Type: application/json'
MegaService
curl http://${host_ip}:3008/v1/searchqna -H "Content-Type: application/json" -d '{ "messages": "What is the latest news? Give me also the source link.", "stream": "true" }'
Nginx Service
curl http://${host_ip}:${NGINX_PORT}/v1/searchqna \ -H "Content-Type: application/json" \ -d '{ "messages": "What is the latest news? Give me also the source link.", "stream": "true" }'
Launch the UI¶
Access the UI at http://${EXTERNAL_HOST_IP}:${SEARCH_FRONTEND_SERVICE_PORT}. A page should open when navigating to this address.

The appearance of such a page indicates that the service is operational and responsive, allowing functional UI testing to proceed.
Let’s enter the task for the service in the “Enter prompt here” field. For example, “What is DeepLearning?” and press Enter. After that, a page with the result of the task should open:
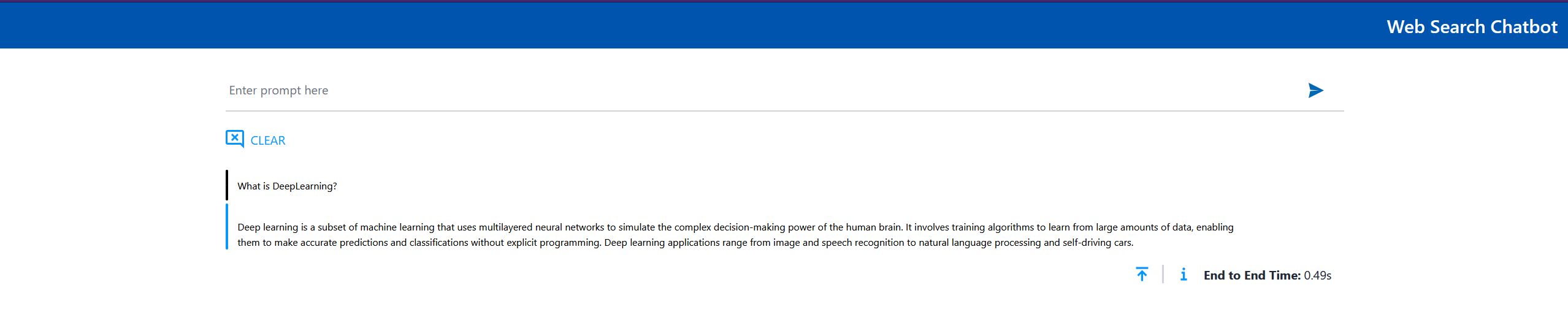 A correct result displayed on the page indicates that the UI service has been successfully verified.
A correct result displayed on the page indicates that the UI service has been successfully verified.
Conclusion¶
This guide should enable developers to deploy the default configuration or any of the other compose yaml files for different configurations. It also highlights the configurable parameters that can be set before deployment.