Deploy Finance Agent on Intel® Xeon® Scalable processors with Docker Compose¶
This README provides instructions for deploying the Finance Agent application using Docker Compose on systems equipped with Intel® Xeon® Scalable processors.
Table of Contents¶
Overview¶
This guide focuses on running the pre-configured Finance Agent service using Docker Compose on Intel® Xeon® Scalable processors. It runs with OpenAI LLM models, along with containers for other microservices like embedding, retrieval, data preparation and the UI.
Prerequisites¶
Docker and Docker Compose installed.
Intel® Xeon® Scalable processors on-prem or from the cloud.
If running OpenAI models, generate the API key by following these instructions. If using a remote server i.e. for LLM text generation, have the base URL and API key ready from the cloud service provider or owner of the on-prem machine.
Git installed (for cloning repository).
Hugging Face Hub API Token (for downloading models).
Access to the internet (or a private model cache).
Finnhub API Key. Go to https://finnhub.io/ to get your free api key.
Financial Datasets API Key. Go to https://docs.financialdatasets.ai/ to get your free api key.
Clone the GenAIExamples repository:
mkdir /path/to/your/workspace/
export WORKDIR=/path/to/your/workspace/
cd $WORKDIR
git clone https://github.com/opea-project/GenAIExamples.git
cd GenAIExamples/FinanceAgent/docker_compose/intel/cpu/xeon
Start Deployment¶
By default, it will run models from OpenAI.
Configure Environment¶
Set required environment variables in your shell:
# Path to your model cache
export HF_CACHE_DIR="./data"
# Some models from Hugging Face require approval beforehand. Ensure you have the necessary permissions to access them.
export HF_TOKEN="your_huggingface_token"
export OPENAI_API_KEY="your-openai-api-key"
export FINNHUB_API_KEY="your-finnhub-api-key"
export FINANCIAL_DATASETS_API_KEY="your-financial-datasets-api-key"
# Configure HOST_IP
# Replace with your host's external IP address (do not use localhost or 127.0.0.1).
export HOST_IP=$(hostname -I | awk '{print $1}')
# Optional: Configure proxy if needed
# export HTTP_PROXY="${http_proxy}"
# export HTTPS_PROXY="${https_proxy}"
# export NO_PROXY="${NO_PROXY},${HOST_IP}"
source set_env.sh
Note: The compose file might read additional variables from set_env.sh. Ensure all required variables like ports (LLM_SERVICE_PORT, TEI_EMBEDDER_PORT, etc.) are set if not using defaults from the compose file. For instance, edit the set_env.sh or overwrite LLM_MODEL_ID to change the LLM model.
[Optional] Running LLM models with remote endpoints¶
When models are deployed on a remote server, a base URL and an API key are required to access them. To set up a remote server and acquire the base URL and API key, refer to Intel® AI for Enterprise Inference offerings.
Note: For FinanceAgent, the minimum hardware requirement for the remote server is Intel® Gaudi® AI Accelerators.
Set the following environment variables.
REMOTE_ENDPOINTis the HTTPS endpoint of the remote server with the model of choice (i.e. https://api.example.com). Note: If the API for the models does not use LiteLLM, the second part of the model card needs to be appended to the URL. For example, setREMOTE_ENDPOINTto https://api.example.com/Llama-3.3-70B-Instruct if the model card ismeta-llama/Llama-3.3-70B-Instruct.OPENAI_LLM_MODEL_IDis the model card which may need to be overwritten depending on what it is set toset_env.sh.
export REMOTE_ENDPOINT=<https-endpoint-of-remote-server>
export OPENAI_LLM_MODEL_ID=<model-card>
OPENAI_API_KEY should already be set in the previous step.
After setting these environment variables, run docker compose by adding compose_remote.yaml as an additional YAML file in the next step.
Start Services¶
The following services will be launched:
tei-embedding-serving
redis-vector-db
redis-kv-store
dataprep-redis-server-finance
finqa-agent-endpoint
research-agent-endpoint
docsum-vllm-xeon
supervisor-agent-endpoint
agent-ui
Follow ONE option below to deploy these services.
Option 1: Deploy with Docker Compose for OpenAI Models¶
docker compose -f compose_openai.yaml up -d
[Optional] Option 2: Deploy with Docker Compose for Models on a Remote Server¶
docker compose -f compose_openai.yaml -f compose_remote.yaml up -d
[Optional] Build docker images¶
This is only needed if the Docker image is unavailable or the pull operation fails.
cd $WORKDIR/GenAIExamples/FinanceAgent/docker_image_build
# get GenAIComps repo
git clone https://github.com/opea-project/GenAIComps.git
# build the images
docker compose -f build.yaml build --no-cache
Validate Services¶
Wait several minutes for models to download and services to initialize. Check container logs with this command:
docker compose logs -f <service_name>.
Validate Data Services¶
Ingest data and retrieval from database
python3 $WORKDIR/GenAIExamples/FinanceAgent/tests/test_redis_finance.py --port 6007 --test_option ingest
python3 $WORKDIR/GenAIExamples/FinanceAgent/tests/test_redis_finance.py --port 6007 --test_option get
Validate Agents¶
FinQA Agent:
export agent_port="9095"
prompt="What is Gap's revenue in 2024?"
python3 $WORKDIR/GenAIExamples/FinanceAgent/tests/test.py --prompt "$prompt" --agent_role "worker" --ext_port $agent_port
Research Agent:
export agent_port="9096"
prompt="generate NVDA financial research report"
python3 $WORKDIR/GenAIExamples/FinanceAgent/tests/test.py --prompt "$prompt" --agent_role "worker" --ext_port $agent_port --tool_choice "get_current_date" --tool_choice "get_share_performance"
Supervisor Agent single turns:
export agent_port="9090"
python3 $WORKDIR/GenAIExamples/FinanceAgent/tests/test.py --agent_role "supervisor" --ext_port $agent_port --stream
Supervisor Agent multi turn:
export agent_port="9090"
python3 $WORKDIR/GenAIExamples/FinanceAgent/tests/test.py --agent_role "supervisor" --ext_port $agent_port --multi-turn --stream
Accessing the User Interface (UI)¶
The UI microservice is launched in the previous step with the other microservices.
To see the UI, open a web browser to http://${HOST_IP}:5175 to access the UI. Note the HOST_IP here is the host IP of the UI microservice.
Create Admin Account with a random value
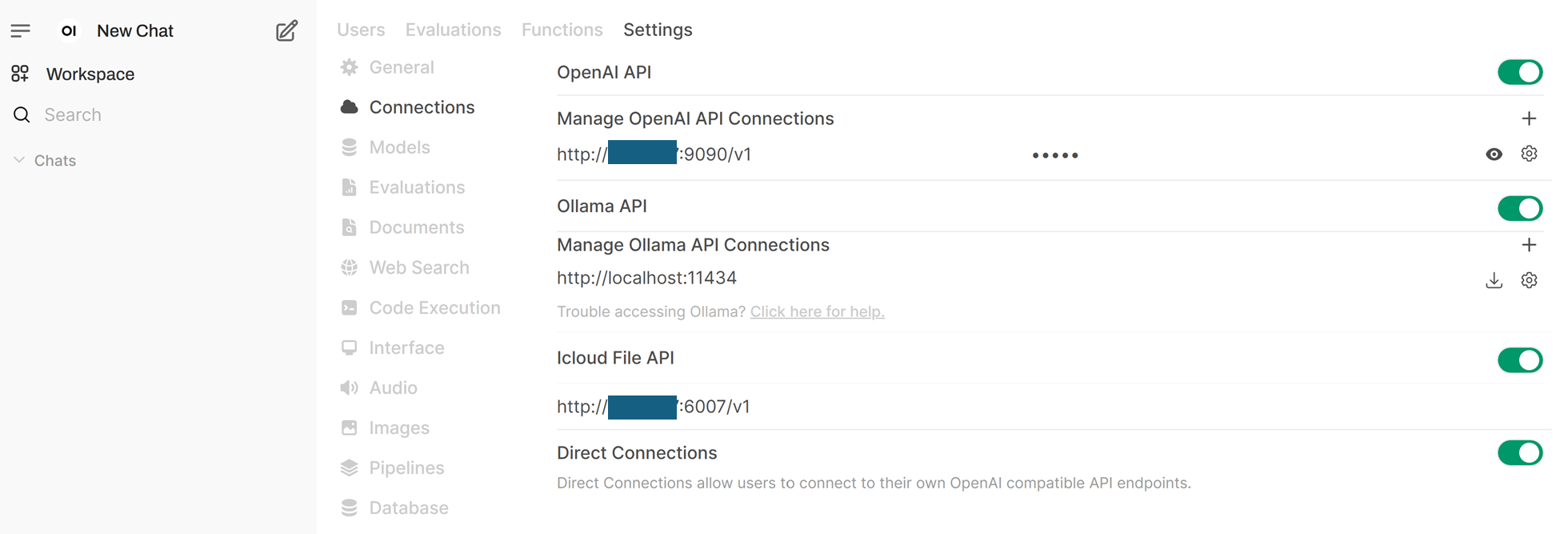
Enter the endpoints in the
ConnectionssettingsFirst, click on the user icon in the upper right corner to open
Settings. Click onAdmin Settings. Click onConnections.Then, enter the supervisor agent endpoint in the
OpenAI APIsection:http://${HOST_IP}:9090/v1. Enter the API key as “empty”. Add an arbitrary model id inModel IDs, for example, “opea_agent”. TheHOST_IPhere should be the host ip of the agent microservice.Then, enter the dataprep endpoint in the
Icloud File APIsection. You first need to enableIcloud File APIby clicking on the button on the right to turn it into green and then enter the endpoint url, for example,http://${HOST_IP}:6007/v1. TheHOST_IPhere should be the host ip of the dataprep microservice.You should see screen like the screenshot below when the settings are done.
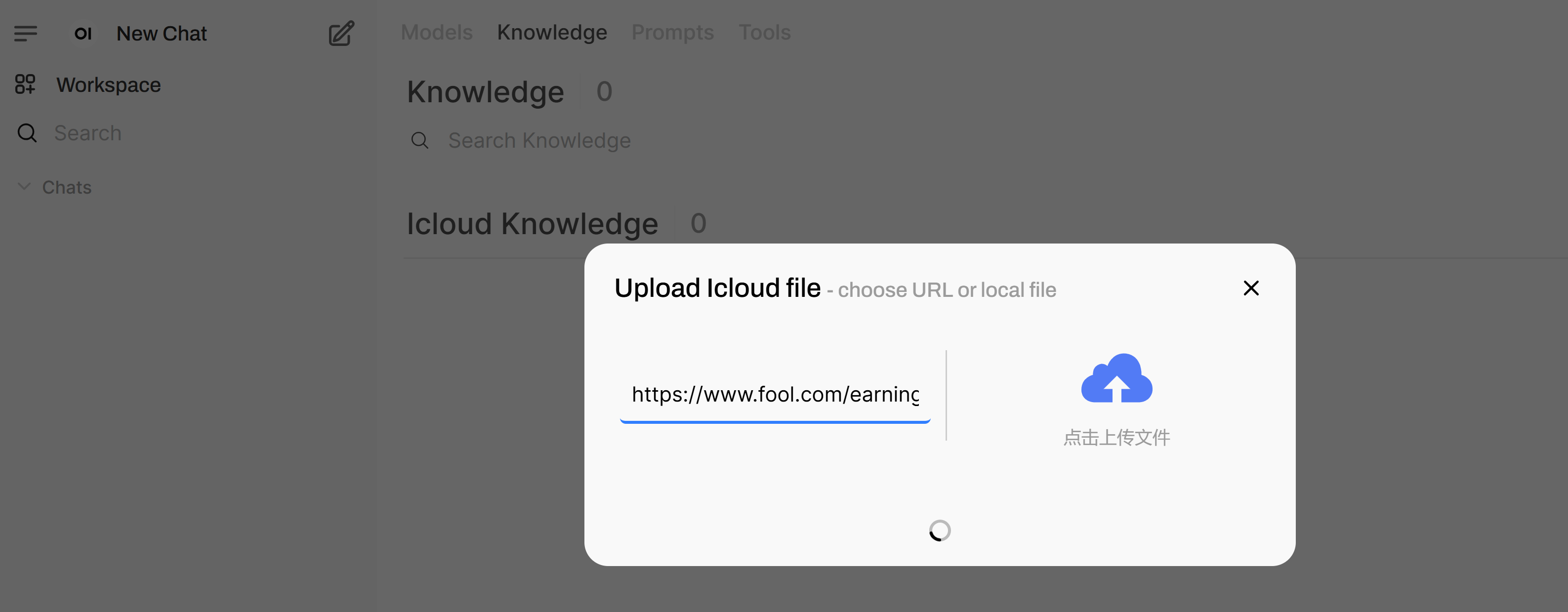
Upload documents with UI
Click on the
Workplaceicon in the top left corner. ClickKnowledge. Click on the “+” sign to the right ofiCloud Knowledge. You can paste an url in the left hand side of the pop-up window, or upload a local file by click on the cloud icon on the right hand side of the pop-up window. Then click on theUpload Confirmbutton. Wait till the processing is done and the pop-up window will be closed on its own when the data ingestion is done. See the screenshot below. Then, enter the dataprep endpoint in theiCloud File APIsection. You first need to enableiCloud File APIby clicking on the button on the right to turn it into green and then enter the endpoint url, for example,http://${HOST_IP}:6007/v1. TheHOST_IPhere should be the host ip of the dataprep microservice. Note: the data ingestion may take a few minutes depending on the length of the document. Please wait patiently and do not close the pop-up window.
Test agent with UI
After the settings are done and documents are ingested, you can start to ask questions to the agent. Click on the
New Chaticon in the top left corner, and type in your questions in the text box in the middle of the UI.The UI will stream the agent’s response tokens. You need to expand the
Thinkingtab to see the agent’s reasoning process. After the agent made tool calls, you would also see the tool output after the tool returns output to the agent. Note: it may take a while to get the tool output back if the tool execution takes time.
