24-10-02-GenAIExamples-001-Image_and_Audio_Support_in_MultimodalQnA¶
Status¶
Under review
Objective¶
The MultimodalQnA megaservice in GenAIExamples currently supports text queries with a response based on the context derived from a collection of videos. This RFC expands upon that and proposes the addition of images, images with text, and audio data types for both the ingested data and the user query.
Motivation¶
As the Multimodal RAG RFC explains, enterprises use multimodal data and the proposed enhancement will increase the variety of use cases that the MultimodalQnA example will be able to support.
Expanding on the types of supported data types will enable use cases such as:
Voice Query and Response: A user wants to query and chat with a multimodal data store using speech as input and get responses returned as speech audio output. Supporting this use case would make the application more accessible to those who cannot see or read and safer for those who are driving a vehicle.
QnA with Speech Audio Files: A user wants to query and chat with a collection of audio files, such as a podcast library.
QnA with Captioned/Labeled Images: A user would like to populate the database with images that have labels, such as “normal” and “abnormal” radiology images, or user-provided captions, like radiologist’s notes, and then query with a new image to find similar ones. After retrieving the most similar image, the system could predict the new image’s label (i.e. assist with diagnosis).
QnA with Multimodal PDFs: A user wants to query and chat with the contents of one or more PDF files, like books, journal articles, business reports, or travel brochures. The PDFs could contain images with or without captions and charts that include titles and descriptions.
Design Proposal¶
There are two phases in the MultimodalQnA example that need to be considered:
Data ingestion and prep
User query
Both of these phases are affected by the enhancements in this RFC. The design for expanding the types of multimodal data for data ingestion and user queries are outlined in the next couple of sections.
There is also a Gradio user interface (UI) that allows the user to both upload data for ingestion and submit queries based on the context in the database. The introduction of different data types will affect the UI design, and the proposed changes are discussed in the UI section.
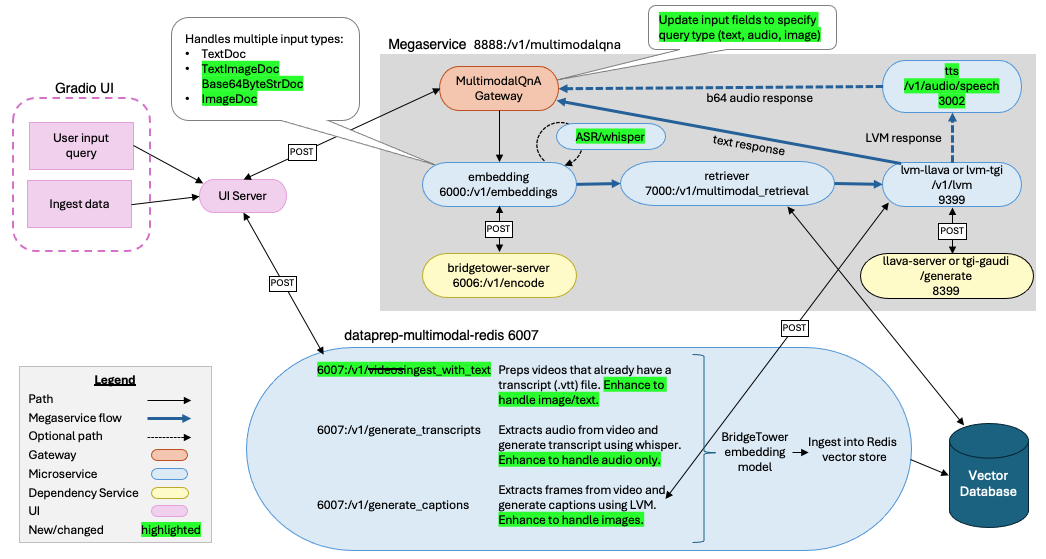
Data Ingestion and Prep¶
In the data ingestion and prep phase, a collection of multimodal data is uploaded to a vector database to be retrieved and used as context for the subsequent queries. From a user’s perspective, they will be able to upload:
Videos with spoken audio (already supported)
Videos without spoken audio (already supported)
Videos with transcriptions (already supported)
Images with text (proposed)
Images without text (proposed)
Spoken audio files (proposed)
PDF files (proposed)
The BridgeTower model which is already utilized by MultimodalQnA merges visual and text data into a unified semantic space. As it works today, the videos being ingested are preprocessed into a list of frames with their corresponding transcript or captions that were generated based on the video. Those frames and their metadata are stored in the vector store, which is used in a RAG pipeline as context for the user’s queries. The addition of image and text are analogous to the video frames and transcripts, and the CV2 VideoCapture library, which is already used by the multimodal data prep code works for both video and images files. The existing video ingestion endpoints can be updated to also handle image ingestion. Similarly, PDF files can be thought of as another form of images and text which can be processed with a library such as PyMuPDF (fitz). There is already an example of such PDF processing in this dataprep microservice which may be reusable. Spoken audio files can be translated to text using the whisper model, similar to how videos with spoken audio use the whisper model to generate transcripts for the video. This means that although the user will be able to upload several different forms of media, once it gets to the embedding model it is all images and text.
The table below lists the endpoints for the multimodal redis langchain data prep microservice that will be changing with this proposal.
Endpoint |
Data type |
Description |
|---|---|---|
|
Videos with transcripts and images with text |
For video with transcripts, gets the video file with their corresponding transcript file (.vtt), and then extracts frames and saves annotations. The image with text would be treated like a single frame with transcript. The data and metadata are prepared for ingestion and then added to the Redis vector store. |
|
Videos with spoken audio and audio only |
For videos with spoken audio, data prep extracts the audio from the video and then generates a transcript (.vtt) using the whisper model. For audio only, the transcript would also be generated using the whisper model. The data and metadata are prepared for ingestion and then added to the Redis vector store. |
|
Videos without spoken audio (i.e. background music, silent movie) and images without text |
For videos, data prep extracts frames from the video and uses the LVM microservice to generate captions for the frames. An image will be treated similarly to a video frame, and the LVM will be used to generate a caption for the image. The data and metadata are prepared for ingestion and then added to the Redis vector store. |
|
PDF files |
Ingests a PDF and then uses these utils to extract chunks of text, images, and tables. The data and metadata are prepared for ingestion and then added to the Redis vector store. |
|
Multimodal |
Lists names of uploaded files. |
|
Multimodal |
Deletes all the uploaded files. |
User Query¶
After the vector database has been populated, the user can then submit a query to the MultimodalQnA megaservice. From the user’s perspective, the query can be:
Text (already supported)
Spoken audio files (proposed)
Image and text (proposed)
The response from the query is:
Text (already supported)
Video clip (already supported)
Single image frame (proposed)
Spoken audio file (proposed)
The ASR microservice which uses the whisper model, converts speech to text and provides a clear line of sight for adding support for spoken audio queries. Once the audio has been converted to text, submitting the query would be no different than how the text queries work today.
The TTS microservice provides the capability to translate text to speech, which would allow the megaservice to return a spoken audio file response.
Changes to the user query flow will involve the following components:
The details explaining the specific changes to these components are given in the sections below.
The option for providing a spoken response could be provided as a flag when starting the megaservice, simliar to how
ChatQnA is able to start with or without reranking, or with or without guardrails. If the MultimodalQnA megaservice is
started with the spoken responses feature, then an additional node for TTS would be added to the DAG. To enable this
option, we would be adding a boolean python argument to the MultimodalQnaService class,
a second Dockerfile that uses that speech response flag in its entrypoint, and another docker compose yaml file that
starts the tts-service and speecht5-service containers.
MultimodalQnAGateway¶
Currently, the MultimodalQnAGateway class analyzes the input message from the request coming in to determine if it’s a first query or a follow up query. Initial queries have a single prompt string, whereas follow up queries have a list of prompts and images.
When introducing different types of data for user queries, we will need to change the inital query from a string to a dictionary in order to comprehend data type and handle multiple items (image, text, audio).
Embedding Microservice¶
The embedding microservice endpoint
gets input as a MultimodalDoc.
The MultimodalDoc is a union of: TextDoc, ImageDoc, and TextImageDoc. In order to accomodate audio input, we
will add Base64ByteStrDoc to the union.
If the embedding service gets a Base64ByteStrDoc as input, it will assume that this is audio only input, and then use
the ASR microservice to
convert the audio to text using the whisper model. After getting the text, the rest of the embedding microservice flow
would work the same as it would for a text query.
UI¶
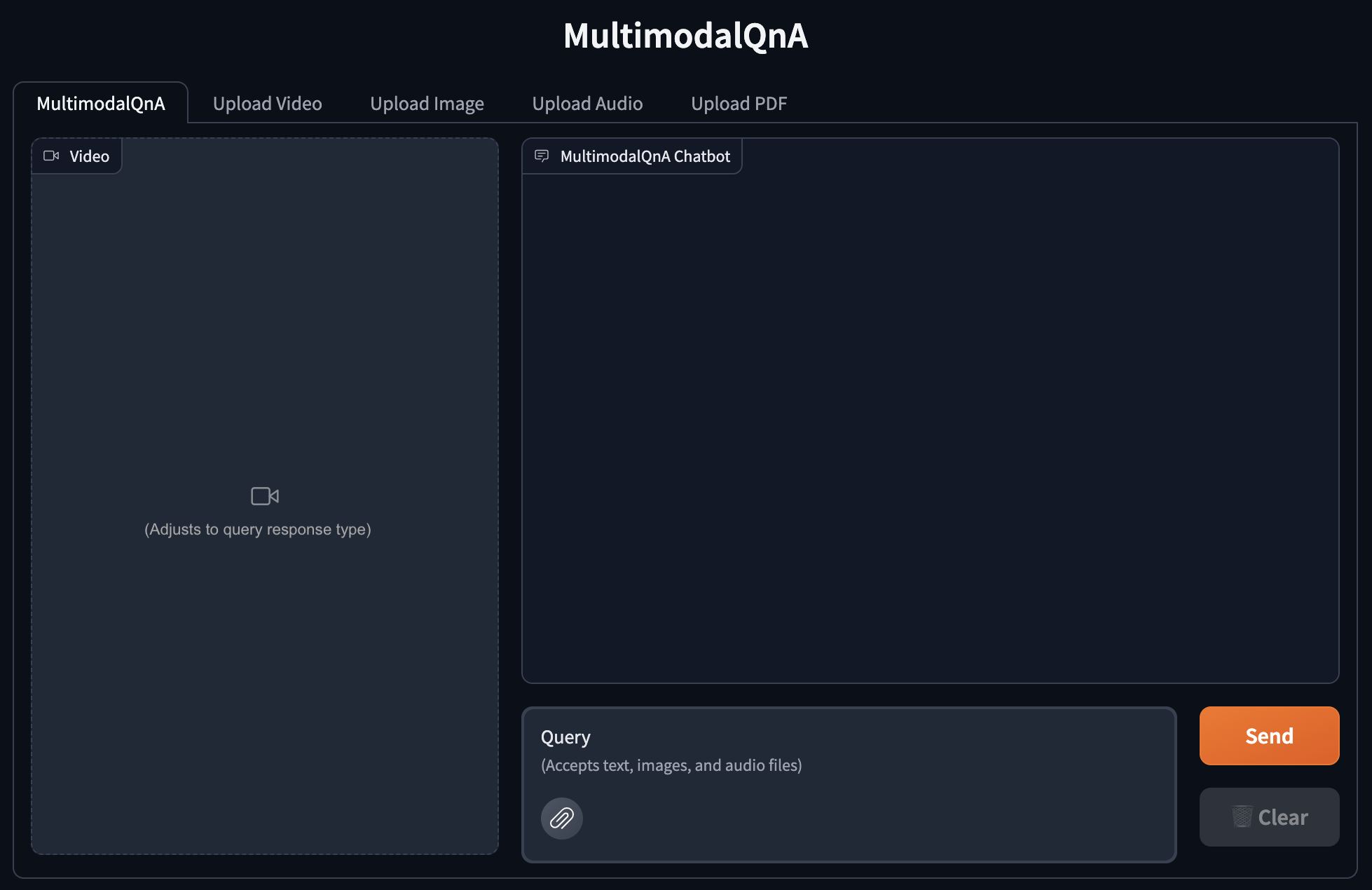
The existing UI shows two modes of video upload capability - with transcripts and with captions, on different interface tabs - and a main chat tab holding the text QnA conversation, a video clip area populated from the first response of a chat session, a small text box for queries, a submit button, and a clear button. Our proposed changes to the UI aim to achieve three goals:
Change the existing design as little as possible
Visually organize and emphasize the enhanced multimodal options for file upload, query input, and query response
Streamline some of the titles and text headings
We list each proposed change in detail below and then provide mockups of the new screens.
UI Changes¶
Modify the main chat screen with a dynamic media display area capable of supporting video, image, or audio results and adjusting automatically when a new type is returned by the gateway.
Modify the query text box to allow multimodal file uploads in addition to text (likely with the Gradio MultimodalTextBox element), expanding the query input to accept images and audio in addition to text.
Simplify the tab titles and screen headings for improved clarity.
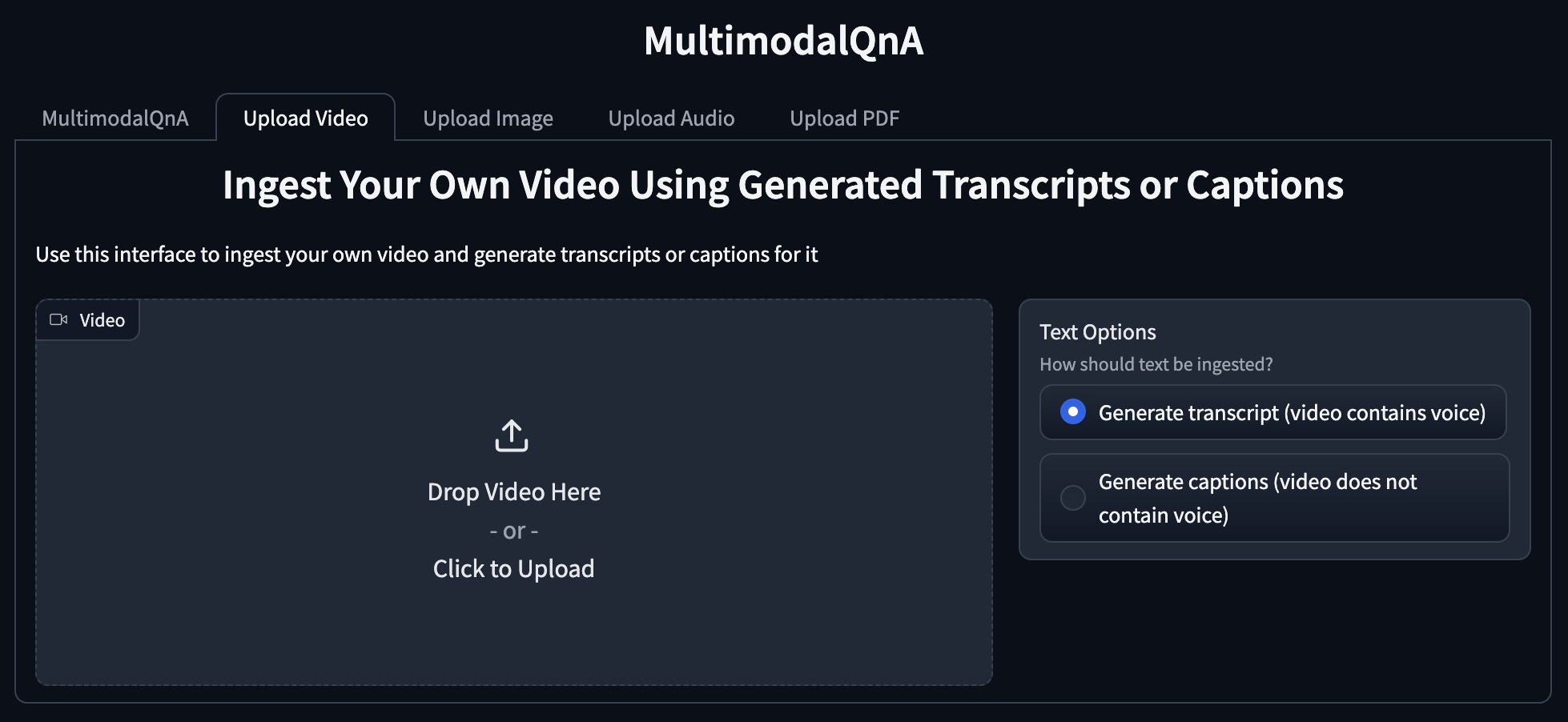
Combine the two modes of video upload into one tab with radio buttons that enable users to choose the correct ingestion endpoint for their videos.
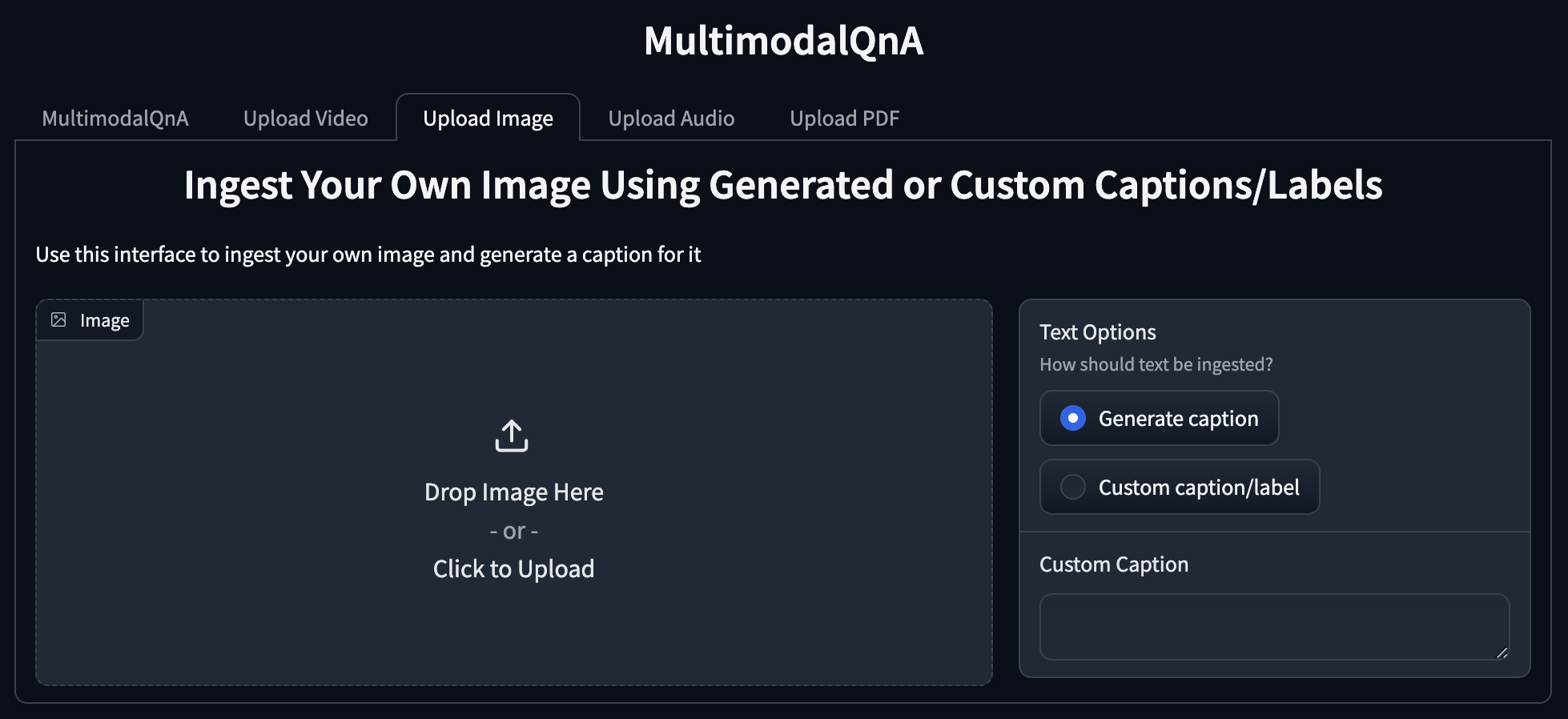
Add a new tab for image uploads with radio buttons allowing users to choose between caption generation and custom label or caption, as well as a text box for uploading a custom label or caption.
Add a new audio upload tab allowing the user to post audio files. The system will assume that the audio contains speech and generate a transcript by default, but this could be expanded to accommodate non-speech audio and/or optional custom labels or captions in the future.
Add a new tab for PDF uploads, which currently is envisioned as one endpoint without any input options.
UI Mockups¶
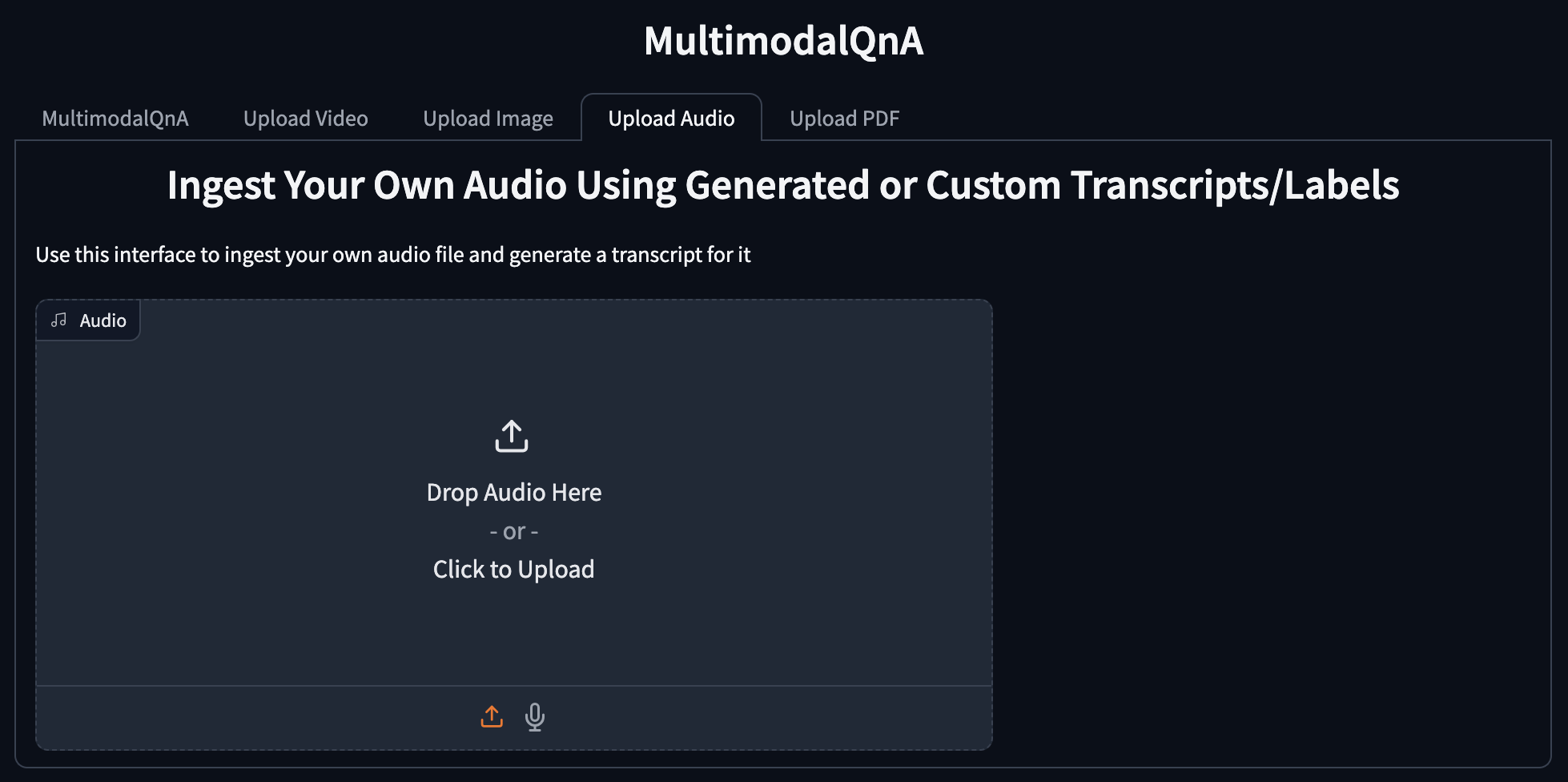
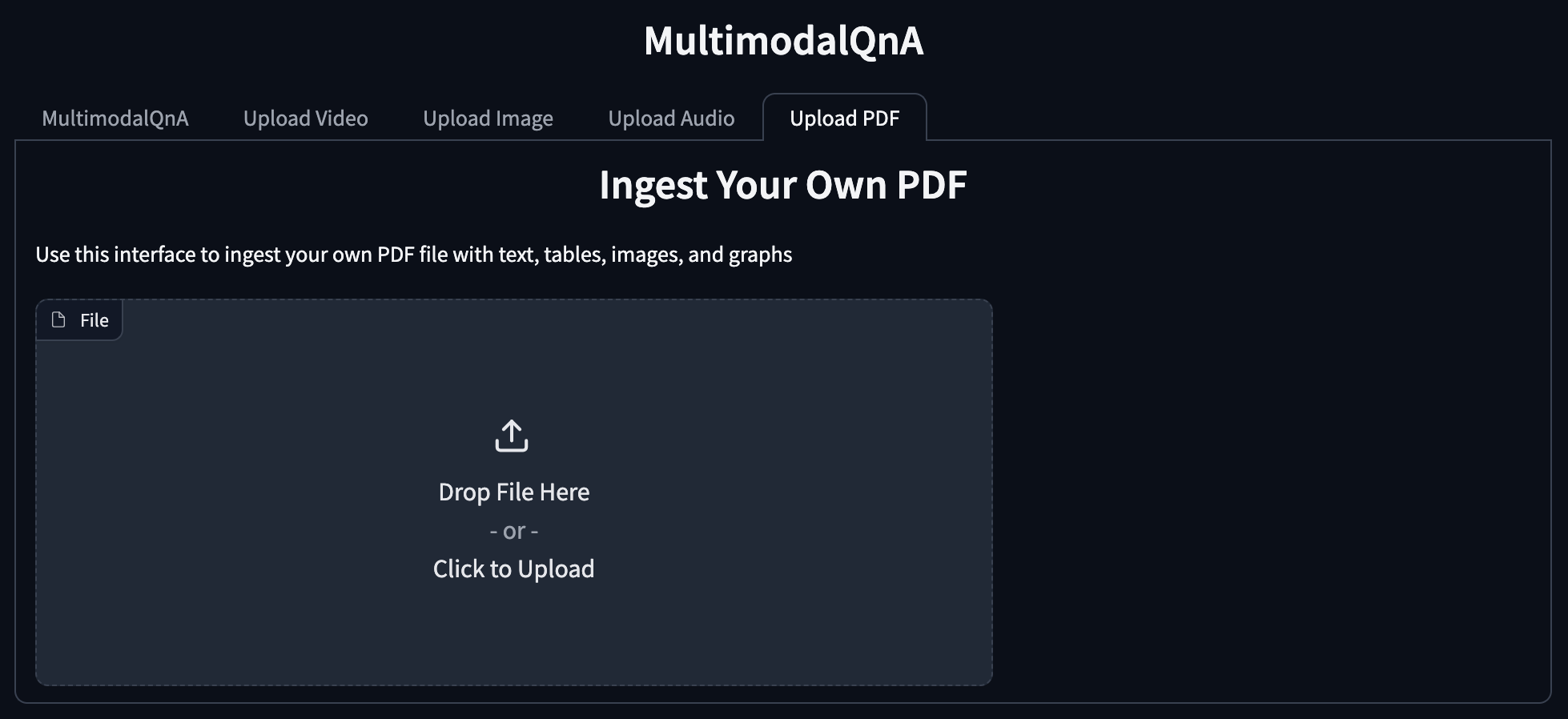
Other Enhancements¶
Model Selection¶
We are proposing an enhancement that allows the user to select the LVM model and embedding model. To do this,
we will enable the functionality for users to specify the container’s entry point in such a way that enables a
user to pass in and change values of default script arguments for the respective python script. Users can change
and interact with these arguments in the set_env.sh with environment variables such as LVM_MODEL before being
officially passed in and overwritten into the dockerfile
entry point when building compose.yaml. The purpose of this change is to allow users to utilize more script arguments
that currently are hard set to their default values when a container is built.
Alternatives Considered¶
The following alternatives can be considered:
We are proposing to use the ASR microservice, which would add two more containers (
opea/asrandopea/whisper/opea/whisper-gaudi) to thecompose.yamlfile, and when using Gaudi, the whisper service container would use one HPU. Instead of having the embedding microservice use ASR, it could directly use the whisper model (similar to how the multimodal data prep uses the whisper model to transcribe video audio). However, using the whisper model directly from a container running on CPU (like the embedding service or data prep) means that we aren’t getting the performance benefits of Gaudi when converting speech-to-text with the whisper model.In data prep, we could have separate endpoints for different types of media. For example, instead of having
/v1/ingest_with_text, we could break that out into/v1/videos_with_transcriptand/v1/images_with_textseparately.Instead of renaming endpoints in the multimodal redis langchain data prep (like
/v1/dataprep/get_videosrenamed to/v1/dataprep/get_filesand/v1/dataprep/delete_videosrenamed to/v1/dataprep/delete_files), we could leave the existing endpoint paths as is, and then add onget_filesanddelete_files. This would help to preserve some backwards compatibility for any applications outside of GenAIExamples who may be using those endpoints. If we decide to do it this way, we could add comments in the code and documentation about the eventual deprecation ofdelete_videosandget_videosif the end goals is to keep only the more generalget_filesanddelete_filesendpoint paths.Instead of different UI screens for the different types of data ingestion (video, image, audio, etc.), there could be one unified “Upload Documents” screen. This would result in a longer page with multiple sections for the different file types and would benefit users who prefer having to scroll over having to click.
Compatibility¶
Interface changes are being made to the following components:
MultimodalQnA gateway
Embeddings multimodal langchain
Dataprep multimodal redis langchain
At the time that this RFC is written, there aren’t any other megaservices in GenAIExamples that are using the Embeddings multimodal langchain or the Dataprep multimodal redis langchain microservices. During implementation, we will do another search of the repo to make sure that other megaservices are not affected by our changes, and if they are we will make changes accordingly.
Miscellaneous¶
Development Phases¶
We have planned the following development phases based on the priority of the features and their development effort:
Phase 1
Data prep and ingestion:
Accept image only
Accept image and text
Accept speech audio only
Query enhancements:
Accept speech audio only
Other enhancements:
Allow the user to choose the embedding model and LVM when starting the services
Phase 2
Data prep and ingestion:
Accept image and text as a PDF
Query enhancements:
Accept image and text
Accept image and speech audio
Phase 3
Data prep and ingestion:
Accept image and speech audio
Other enhancements:
Support for spoken audio responses (text-to-speech)
Future ideas:
Data prep and ingestion:
Accept non-speech audio
Accept Powerpoint slides and other file types
Query enhancements:
Accept speech audio and non-speech audio