Example Arbitration Post-Hearing Assistant deployments on AMD GPU (ROCm)¶
This document outlines the deployment process for a Arbitration Post-Hearing Assistant application utilizing OPEA components on an AMD GPU server.
This example includes the following sections:
Arbitration Post-Hearing Assistant Quick Start Deployment: Demonstrates how to quickly deploy a Arbitration Post-Hearing Assistant application/pipeline on AMD GPU platform.
Arbitration Post-Hearing Assistant Docker Compose Files: Describes some example deployments and their docker compose files.
Arbitration Post-Hearing Assistant Detailed Usage: Provide more detailed usage.
Launch the UI: Guideline for UI usage
arb-post-hearing-assistant Quick Start Deployment¶
This section describes how to quickly deploy and test the Arbitration Post-Hearing Assistant service manually on an AMD GPU platform. The basic steps are:
Access the Code¶
Clone the GenAIExample repository and access the Arbitration Post-Hearing Assistant AMD GPU platform Docker Compose files and supporting scripts:
git clone https://github.com/opea-project/GenAIExamples.git
cd GenAIExamples/ArbPostHearingAssistant/docker_compose/amd/gpu/rocm
Generate a HuggingFace Access Token¶
Some HuggingFace resources, such as some models, are only accessible if you have an access token. If you do not already have a HuggingFace access token, you can create one by first creating an account by following the steps provided at HuggingFace and then generating a user access token.
Configure the Deployment Environment¶
To set up environment variables for deploying Arbitration Post-Hearing Assistant services, set up some parameters specific to the deployment environment and source the set_env_*.sh script in this directory:
if used vLLM - set_env_vllm.sh
if used TGI - set_env.sh
Set the values of the variables:
HOST_IP, HOST_IP_EXTERNAL - These variables are used to configure the name/address of the service in the operating system environment for the application services to interact with each other and with the outside world.
If your server uses only an internal address and is not accessible from the Internet, then the values for these two variables will be the same and the value will be equal to the server’s internal name/address.
If your server uses only an external, Internet-accessible address, then the values for these two variables will be the same and the value will be equal to the server’s external name/address.
If your server is located on an internal network, has an internal address, but is accessible from the Internet via a proxy/firewall/load balancer, then the HOST_IP variable will have a value equal to the internal name/address of the server, and the EXTERNAL_HOST_IP variable will have a value equal to the external name/address of the proxy/firewall/load balancer behind which the server is located.
We set these values in the file set_env****.sh
Variables with names like “******_PORT”** - These variables set the IP port numbers for establishing network connections to the application services. The values shown in the file set_env.sh or set_env_vllm.sh they are the values used for the development and testing of the application, as well as configured for the environment in which the development is performed. These values must be configured in accordance with the rules of network access to your environment’s server, and must not overlap with the IP ports of other applications that are already in use.
Setting variables in the operating system environment:
export HF_TOKEN="Your_HuggingFace_API_Token"
source ./set_env_*.sh # replace the script name with the appropriate one
Consult the section on Arbitration Post-Hearing Assistant Service configuration for information on how service specific configuration parameters affect deployments.
Deploy the Services Using Docker Compose¶
To deploy the Arbitration Post-Hearing Assistant services, execute the docker compose up command with the appropriate arguments. For a default deployment with TGI, execute the command below. It uses the ‘compose.yaml’ file.
cd docker_compose/amd/gpu/rocm
# if used TGI
docker compose -f compose.yaml up -d
# if used vLLM
# docker compose -f compose_vllm.yaml up -d
To enable GPU support for AMD GPUs, the following configuration is added to the Docker Compose file:
compose_vllm.yaml - for vLLM-based application
compose.yaml - for TGI-based
shm_size: 1g
devices:
- /dev/kfd:/dev/kfd
- /dev/dri:/dev/dri
cap_add:
- SYS_PTRACE
group_add:
- video
security_opt:
- seccomp:unconfined
This configuration forwards all available GPUs to the container. To use a specific GPU, specify its cardN and renderN device IDs. For example:
shm_size: 1g
devices:
- /dev/kfd:/dev/kfd
- /dev/dri/card0:/dev/dri/card0
- /dev/dri/render128:/dev/dri/render128
cap_add:
- SYS_PTRACE
group_add:
- video
security_opt:
- seccomp:unconfined
How to Identify GPU Device IDs:
Use AMD GPU driver utilities to determine the correct cardN and renderN IDs for your GPU.
Note: developers should build docker image from source when:
Developing off the git main branch (as the container’s ports in the repo may be different > from the published docker image).
Unable to download the docker image.
Use a specific version of Docker image.
Please refer to the table below to build different microservices from source:
Microservice |
Deployment Guide |
|---|---|
TGI |
|
vLLM |
|
llm-arb-post-hearing-assistant |
|
MegaService |
|
UI |
Check the Deployment Status¶
After running docker compose, check if all the containers launched via docker compose have started:
docker ps -a
For the default deployment, the following 4 containers should have started:
If used TGI:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
24bd78300413 opea/arb-post-hearing-assistant-gradio-ui:latest "python arb_post_hea…" 2 hours ago Up 2 hours 0.0.0.0:5173->5173/tcp, [::]:5173->5173/tcp arb-post-hearing-assistant-xeon-ui-server
59e60c954e26 opea/arb-post-hearing-assistant:latest "python arb_post_hea…" 2 hours ago Up 2 hours 0.0.0.0:8888->8888/tcp, [::]:8888->8888/tcp arb-post-hearing-assistant-xeon-backend-server
32afc12de996 opea/llm-arb-post-hearing-assistant:latest "python comps/arb_po…" 2 hours ago Up 2 hours 0.0.0.0:9000->9000/tcp, [::]:9000->9000/tcp arb-post-hearing-assistant-xeon-llm-server
c8e539360aff ghcr.io/huggingface/text-generation-inference:2.4.0-intel-cpu "text-generation-lau…" 2 hours ago Up 2 hours (healthy) 0.0.0.0:8008->80/tcp, [::]:8008->80/tcp arb-post-hearing-assistant-xeon-tgi-server
Test the Pipeline¶
Once the Arbitration Post-Hearing Assistant services are running, test the pipeline using the following command:
curl -X POST http://${host_ip}:8888/v1/arb-post-hearing \
-H "Content-Type: application/json" \
-d '{"type": "text", [10:00 AM] Arbitrator Hon. Rebecca Lawson: Good morning. This hearing is now in session for Case No. ARB/2025/0917. Lets begin with appearances. [10:01 AM] Attorney Michael Grant for Mr. Jonathan Reed: Good morning Your Honor. I represent the claimant Mr. Jonathan Reed. [10:01 AM] Attorney Lisa Chen for Ms. Rachel Morgan: Good morning. I represent the respondent Ms. Rachel Morgan. [10:03 AM] Arbitrator Hon. Rebecca Lawson: Thank you. Lets proceed with Mr. Reeds opening statement. [10:04 AM] Attorney Michael Grant: Ms. Morgan failed to deliver services as per the agreement dated March 15 2023. We have submitted relevant documentation including email correspondence and payment records. The delay caused substantial financial harm to our client. [10:15 AM] Attorney Lisa Chen: We deny any breach of contract. The delays were due to regulatory issues outside our control. Furthermore Mr. Reed did not provide timely approvals which contributed to the delay. [10:30 AM] Arbitrator Hon. Rebecca Lawson: Lets turn to Clause Z of the agreement. Id like both parties to submit written briefs addressing the applicability of the force majeure clause and the timeline of approvals. [11:00 AM] Attorney Michael Grant: Understood. Well submit by the deadline. [11:01 AM] Attorney Lisa Chen: Agreed. [11:02 AM] Arbitrator Hon. Rebecca Lawson: The next hearing is scheduled for October 22 2025 at 1030 AM Eastern Time. Please ensure your witnesses are available for cross examination. [4:45 PM] Arbitrator Hon. Rebecca Lawson: This session is adjourned. Thank you everyone.","max_tokens":2000,"language":"en"}'
Note The value of host_ip was set using the set_env.sh script and can be found in the .env file.
Cleanup the Deployment¶
To stop the containers associated with the deployment, execute the following command:
docker compose -f compose.yaml down
All the Arbitration Post-Hearing Assistant containers will be stopped and then removed on completion of the “down” command.
arb-post-hearing-assistant Docker Compose Files¶
In the context of deploying a Arbitration Post-Hearing Assistant pipeline on an AMD GPU platform, we can pick and choose different large language model serving frameworks. The table below outlines the various configurations that are available as part of the application.
File |
Description |
|---|---|
Default compose file using tgi as serving framework |
|
The LLM serving framework is vLLM. All other configurations remain the same as the default |
arb-post-hearing-assistant Assistant Detailed Usage¶
There are also some customized usage.
Query with text¶
# form input. Use English mode (default).
curl http://${host_ip}:8888/v1/arb-post-hearing \
-H "Content-Type: multipart/form-data" \
-F "type=text" \
-F "messages=[10:00 AM] Arbitrator Hon. Rebecca Lawson: Good morning. This hearing is now in session for Case No. ARB/2025/0917. Lets begin with appearances. [10:01 AM] Attorney Michael Grant for Mr. Jonathan Reed: Good morning Your Honor. I represent the claimant Mr. Jonathan Reed. [10:01 AM] Attorney Lisa Chen for Ms. Rachel Morgan: Good morning. I represent the respondent Ms. Rachel Morgan. [10:03 AM] Arbitrator Hon. Rebecca Lawson: Thank you. Lets proceed with Mr. Reeds opening statement. [10:04 AM] Attorney Michael Grant: Ms. Morgan failed to deliver services as per the agreement dated March 15 2023. We have submitted relevant documentation including email correspondence and payment records. The delay caused substantial financial harm to our client. [10:15 AM] Attorney Lisa Chen: We deny any breach of contract. The delays were due to regulatory issues outside our control. Furthermore Mr. Reed did not provide timely approvals which contributed to the delay. [10:30 AM] Arbitrator Hon. Rebecca Lawson: Lets turn to Clause Z of the agreement. Id like both parties to submit written briefs addressing the applicability of the force majeure clause and the timeline of approvals. [11:00 AM] Attorney Michael Grant: Understood. Well submit by the deadline. [11:01 AM] Attorney Lisa Chen: Agreed. [11:02 AM] Arbitrator Hon. Rebecca Lawson: The next hearing is scheduled for October 22 2025 at 1030 AM Eastern Time. Please ensure your witnesses are available for cross examination. [4:45 PM] Arbitrator Hon. Rebecca Lawson: This session is adjourned. Thank you everyone." \
-F "max_tokens=2000" \
-F "language=en"
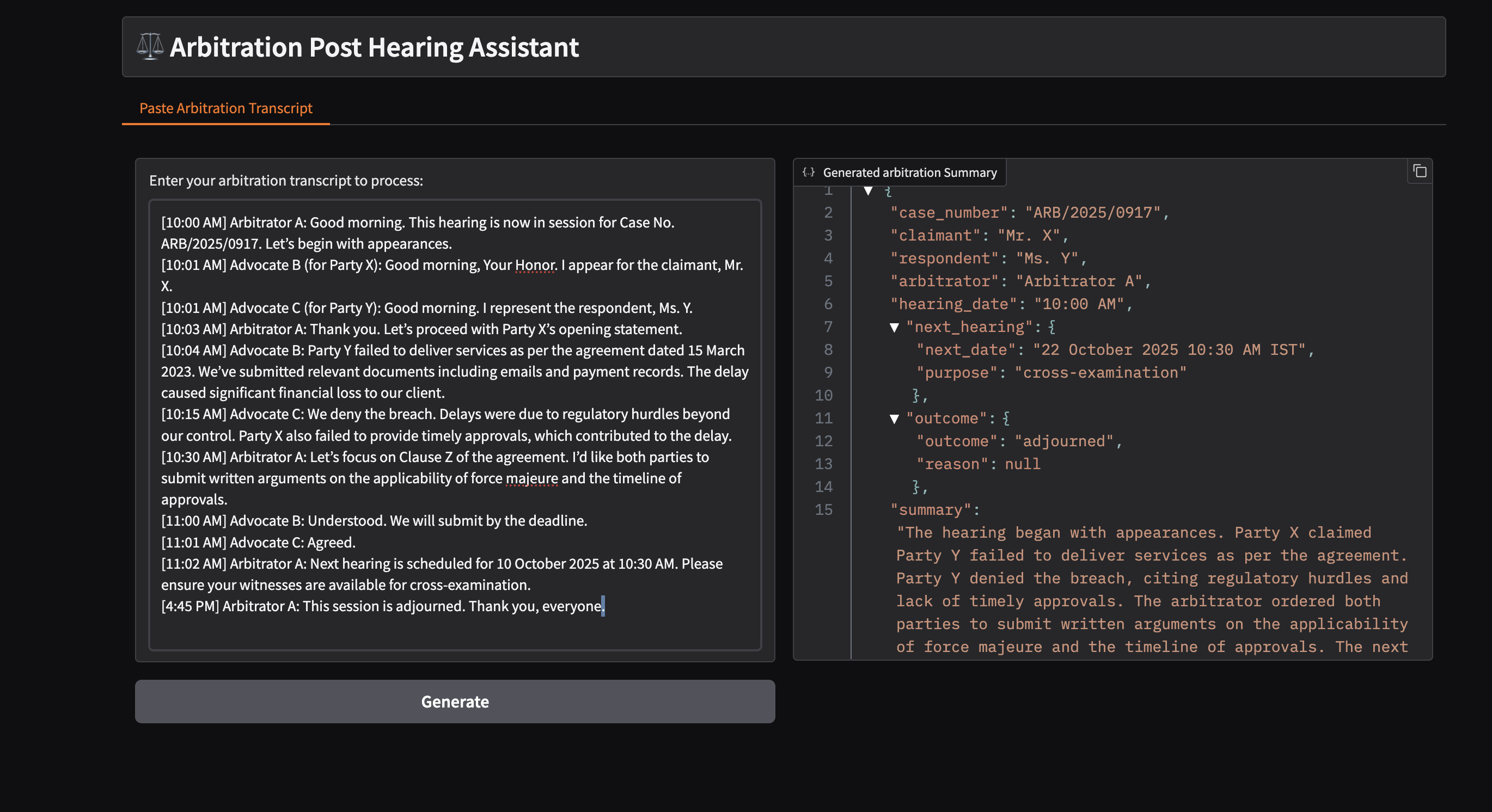
## Launch the UI
### Gradio UI
Open this URL `http://{host_ip}:5173` in your browser to access the Gradio based frontend.
### Profile Microservices
To further analyze MicroService Performance, users could follow the instructions to profile MicroServices.
#### 1. vLLM backend Service
Users could follow previous section to testing vLLM microservice or Arbitration Post-Hearing Assistant MegaService. By default, vLLM profiling is not enabled. Users could start and stop profiling by following commands.
## Conclusion
This guide should enable developer to deploy the default configuration or any of the other compose yaml files for different configurations. It also highlights the configurable parameters that can be set before deployment.