 HELMET: How to Evaluate Long-context Language Models Effectively and Thoroughly¶
HELMET: How to Evaluate Long-context Language Models Effectively and Thoroughly¶
![]() HELMET (How to Evaluate Long-context Models Effectively and Thoroughly) is a comprehensive benchmark for long-context language models covering seven diverse categories of tasks.
The datasets are application-centric and are designed to evaluate models at different lengths and levels of complexity.
Please check out the paper for more details, and this repo will detail how to run the evaluation.
HELMET (How to Evaluate Long-context Models Effectively and Thoroughly) is a comprehensive benchmark for long-context language models covering seven diverse categories of tasks.
The datasets are application-centric and are designed to evaluate models at different lengths and levels of complexity.
Please check out the paper for more details, and this repo will detail how to run the evaluation.
Quick Links¶
Release Progress¶
See CHANGELOG.md for updates and more details.
[x] HELMET Code
[x] HELMET data
[x] VLLM Support
[x] Correlation analysis notebook
[ ] Support >128k input length
[ ] Retrieval setup
Setup¶
Please install the necessary packages with (using a virtual environment is recommended, tested with python 3.11):
python -m venv env
source env/bin/activate
pip install -r requirements.txt
If you want to evalute on NVIDIA GPU, pip install flash-attn as your requirements.
pip install flash-attn
Additionally, if you wish to use the API models, you will need to install the package corresponding to the API you wish to use
pip install openai # OpenAI API (GPT)
pip install anthropic==0.42.0 # Anthropic API (Claude)
pip install google-generativeai # Google API (Gemini)
pip install vertexai==1.71.0 # Google API (Gemini)
pip install together # Together API
You should also set the environmental variables accordingly so the API calls can be made correctly. To see the variable that you should set up, check out model_utils.py and the corresponding class (e.g., GeminiModel).
Data¶
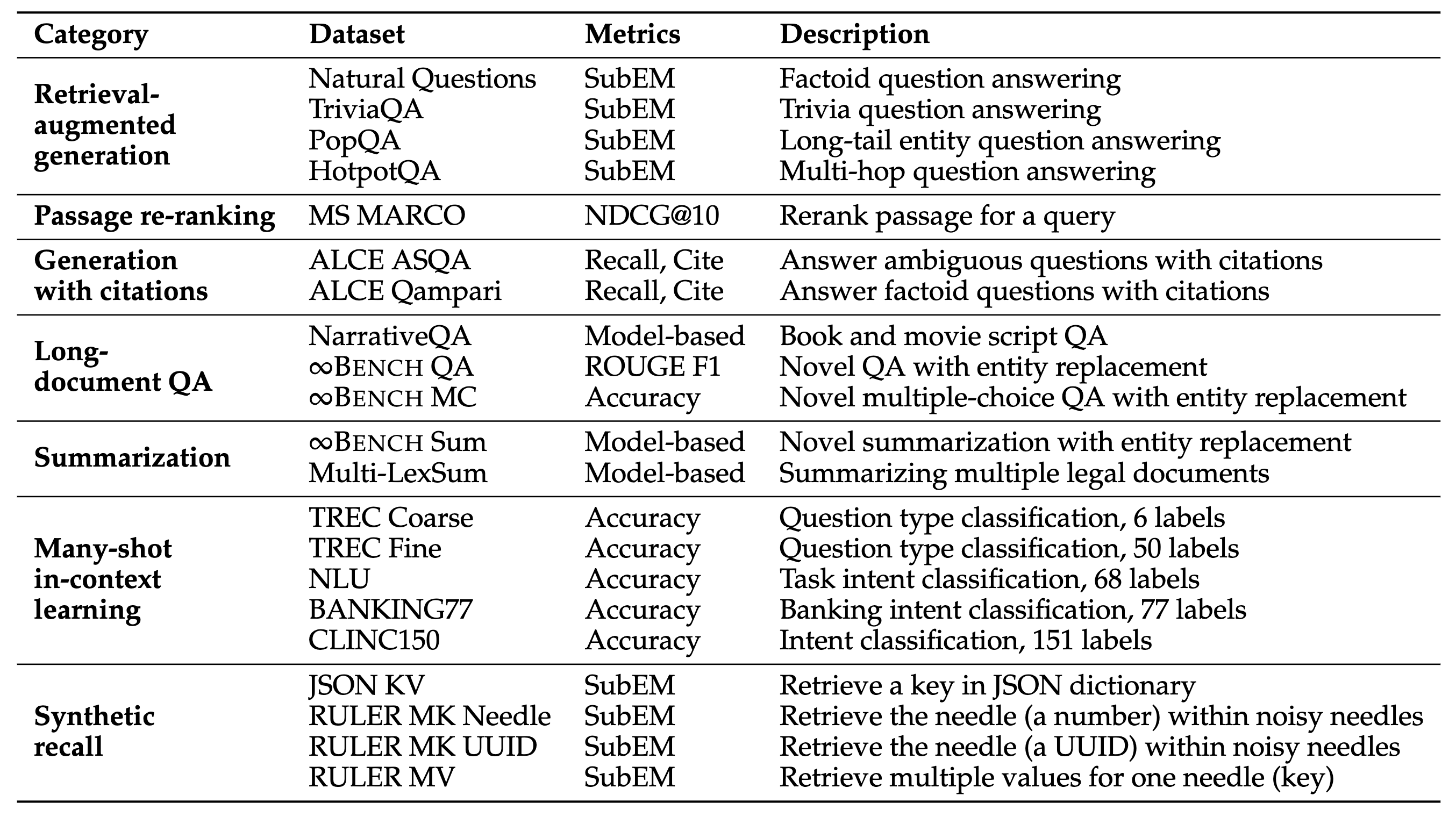
You can download the data with the script:
bash scripts/download_data.sh
This will first download the .tar.gz file and then decompress it to the data directory.
The data is hosted on this Huggingface repo, which stores our preprocessed data in jsonl files and is about 34GB in storage. For Recall, RAG, Passage Re-ranking, and ALCE, we either generate the data ourselves or do retrieval, so these are stored in jsonl files, whereas our script will load the data from Huggingface for the other tasks, LongQA, Summ, and ICL. The data also contains the key points extracted for evaluating summarization with model-based evaluation.
Running evaluation¶
To run the evaluation, simply use one of the config files in the configs directory, you may also overwrite any arguments in the config file or add new arguments simply through the command line (see arguments.py):
for task in recall rag rerank cite longqa summ icl; do
python eval.py --config configs/${task}.yaml \
--model_name_or_path {local model path or huggingface model name} \
--output_dir {output directory, defaults to output/{model_name}} \
--use_chat_template False # only if you are using non-instruction-tuned models, otherwise use the default.
done
This will output the results file under the output directory in two files: .json contains all the data point details while .json.score only contain the aggregated metrics.
For slurm users, you may find our slurm scripts useful:
# I recommend using these slurm scripts as they contain more details (including all the model names) and can be easily modified to fit your setup
# you can also run them in your shell by replacing sbatch with bash, check out the file for more details
sbatch scripts/run_eval_slurm.sh # 128k
sbatch scripts/run_short_slurm.sh # 8k-64k
# for the API models, note that API results may vary due to the randomness in the API calls
bash scripts/run_api.sh
Run on Intel Gaudi¶
If you want to enable the evaluation on vLLM with Intel Gaudi, you can use the following commands:
## Build vllm docker image
cd scripts/vllm-gaudi
bash build_image.sh
## launch vllm container, change `LLM_MODEL_ID` and `NUM_CARDS` as your need
cd scripts/vllm-gaudi
bash launch_container.sh
## evalute
bash scripts/run_eval_vllm_gaudi.sh
Check out the script file for more details! See Others for the slurm scripts, easily collecting all the results, and using VLLM.
The full results from our evaluation are here.
Tested model that we didn’t? Please email me the result files and I will add them to the spreadsheet! See Contacts for my email.
Model-based evaluation¶
To run the model-based evaluation for LongQA and Summarization, please make sure that you have set the environmental variables for OpenAI so you can make calls to GPT-4o, then you can run:
# by default, we assume all output files are stored in output/{model_name}
python scripts/eval_gpt4_longqa.py --model_name_or_path {local model path or huggingface model name} --tag {tag for the model}
python scripts/eval_gpt4_summ.py --model_name_or_path {local model path or huggingface model name} --tag {tag for the model}
# Alternatively, if you want to shard the process
bash scripts/eval_gpt4_longqa.sh
bash scripts/eval_gpt4_summ.sh
Adding new models¶
The existing code supports using HuggingFace-supported models and API models (OpenAI, Anthropic, Google, and Together). To add a new model or use a different framework (other than HuggingFace), you can modify the model_utils.py file.
Specifically, you need to create a new class that implements prepare_inputs (how the inputs are processed) and generate functions. Then, you can add a new case to load_LLM.
Please refer to the existing classes for examples.
Adding new tasks¶
To add a new task/dataset, you just need to modify the data.py file:
Create a function that specifies how to load the data:
Specify the string templates for the task through
user_template,system_template, andprompt_template(which is usually just the concatenation of the two)Process each sample to fit the specified templates (the tokenization code will call
user_template.format(**test_sample)and same forsystem_template). Importantly, each sample should have acontextfield, which will be truncated automatically if the input is too long (e.g., for QA, this is the retrieved passages; for NarrativeQA, this is the book/script). You should use thequestionandanswerfield to make evaluation/printing easier.Optionally, add a
post_processfunction to process the model output (e.g., for MS MARCO, we use a ranking parse function; for RULER, we calculate the recall). There is also adefault_post_processfunction that parses and calculate simple metrics like EM and F1 that you may use. This function should take in the model output and the test sample and return a tuple of(metrics, changed_output), themetrics(e.g., EM, ROUGE) are aggregated across all samples, and thechanged_outputare added to the test_sample and saved to the output file.The function should return
{'data': [list of data samples], 'prompt_template': prompt_template, 'user_template': user_template, 'system_template': system_template, 'post_process': [optional custom function]}.
Finally, simply add a new case to the load_data function that calls the function that you just wrote to load your data.
You can refer to the existing tasks for examples (e.g., load_json_kv, load_narrativeqa, and load_msmarco_rerank).
Dataset correlation analysis¶
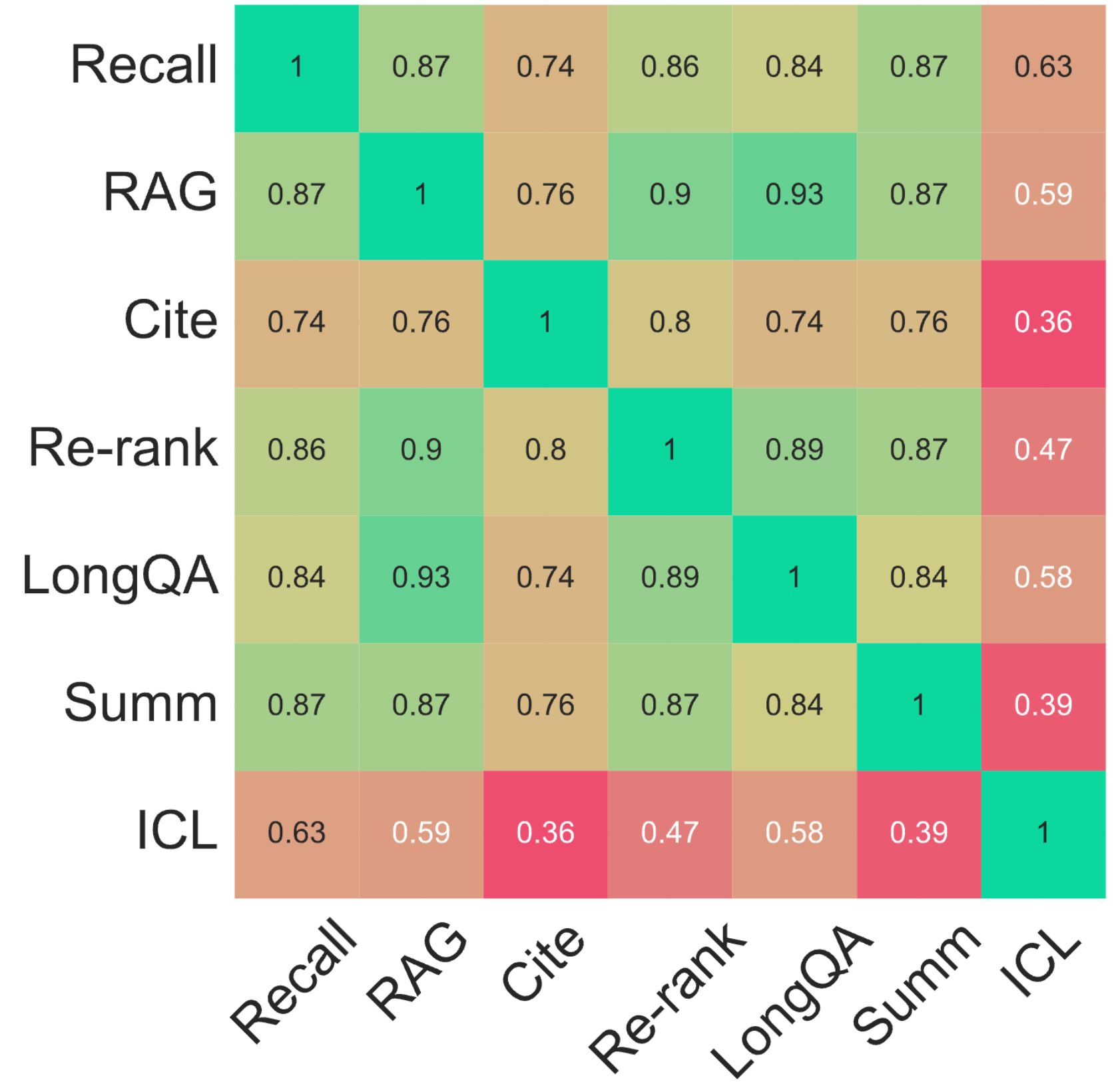
We also analyze the correlation between performance on different datasets. The code will be released soon.
Others¶
Collecting results
To quickly collect all the results, you can use the script:python scripts/collect_results.py
You should check the script for more details and modify the specific fields to fit your needs. For example, you can change the models, task configs, output directories, tags, and more.
Slurm scripts
I have also included the slurm scripts for running all the experiments from the paper. You can run the scripts with:
sbatch scripts/run_eval_slurm.sh
sbatch scripts/run_short_slurm.sh
sbatch scripts/run_api.sh
Note that you may need to modify the script to fit your cluster setup. For example:
--array 0-1specifies the number of jobs to run, this index corresponds to the model index in the array.You may also specify which set of models to run with
MNAME="${S_MODELS[$M_IDX]}"orMNAME="${L_MODELS[$M_IDX]}"for the short and long models respectively.--gres=gpu:1specifies the number of GPUs you want to use, for the larger models, you may need more GPUs (we use up to 8x80GB GPUs).--mail-userspecifies the email address to send the job status to.source env/bin/activatespecifies the virtual environment to use.MODEL_NAME="/path/to/your/model/$MNAME"you should specify the path to your model here.
Using VLLM
To use VLLM to run the evaluation, you can simply add the --use_vllm flag to the command line like so:
python eval.py --config configs/cite.yaml --use_vllm
Disclaimer: VLLM can be much faster than using the native HuggingFace generation; however, we found that the results can be slightly different, so we recommend using the native HuggingFace generation for the final evaluation. All reported results in the paper are from the native HuggingFace generation. The speedup is much more noticable for tasks that generates more tokens (e.g., summarization may see up to 2x speedup), whereas the speedup is less noticable for tasks that generate fewer tokens (e.g., JSON KV may see less than 5% speedup).
Error loading InfiniteBench
If you encounter errors loading the InfiniteBench dataset in different modes (online vs. offline inference), it appears to stem from a bug in the hashing function. To fix this, you can do the following:
cd {cache_dir}/huggingface/datasets/xinrongzhang2022___infinitebench
ln -s default-819c8cda45921923 default-7662505cb3478cd4
Error loading InfiniteBench
If you encounter errors loading the InfiniteBench dataset in different modes (online vs. offline inference), it appears to stem from a bug in the hashing function. To fix this, you can do the following:
cd {cache_dir}/huggingface/datasets/xinrongzhang2022___infinitebench
ln -s default-819c8cda45921923 default-7662505cb3478cd4
Contacts¶
If you have any questions, please email me at hyen@cs.princeton.edu.
If you encounter any problems, you can also open an issue here. Please try to specify the problem with details so we can help you better and quicker!
Citation¶
If you find our work useful, please cite us:
@inproceedings{yen2025helmet,
title={HELMET: How to Evaluate Long-Context Language Models Effectively and Thoroughly},
author={Howard Yen and Tianyu Gao and Minmin Hou and Ke Ding and Daniel Fleischer and Peter Izsak and Moshe Wasserblat and Danqi Chen},
year={2025},
booktitle={International Conference on Learning Representations (ICLR)},
}
Please also cite the original dataset creators, listed below:
Citations
@article{Liu2023LostIT,
title={Lost in the Middle: How Language Models Use Long Contexts},
author={Nelson F. Liu and Kevin Lin and John Hewitt and Ashwin Paranjape and Michele Bevilacqua and Fabio Petroni and Percy Liang},
journal={Transactions of the Association for Computational Linguistics},
year={2023},
volume={12},
pages={157-173},
url={https://api.semanticscholar.org/CorpusID:259360665}
}
@inproceedings{
hsieh2024ruler,
title={{RULER}: What{\textquoteright}s the Real Context Size of Your Long-Context Language Models?},
author={Cheng-Ping Hsieh and Simeng Sun and Samuel Kriman and Shantanu Acharya and Dima Rekesh and Fei Jia and Boris Ginsburg},
booktitle={First Conference on Language Modeling},
year={2024},
url={https://openreview.net/forum?id=kIoBbc76Sy}
}
@inproceedings{mallen-etal-2023-trust,
title = "When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories",
author = "Mallen, Alex and
Asai, Akari and
Zhong, Victor and
Das, Rajarshi and
Khashabi, Daniel and
Hajishirzi, Hannaneh",
editor = "Rogers, Anna and
Boyd-Graber, Jordan and
Okazaki, Naoaki",
booktitle = acl,
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.546",
doi = "10.18653/v1/2023.acl-long.546",
pages = "9802--9822",
}
@inproceedings{yang-etal-2018-hotpotqa,
title = "{H}otpot{QA}: A Dataset for Diverse, Explainable Multi-hop Question Answering",
author = "Yang, Zhilin and
Qi, Peng and
Zhang, Saizheng and
Bengio, Yoshua and
Cohen, William and
Salakhutdinov, Ruslan and
Manning, Christopher D.",
editor = "Riloff, Ellen and
Chiang, David and
Hockenmaier, Julia and
Tsujii, Jun{'}ichi",
booktitle = "Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing",
month = oct # "-" # nov,
year = "2018",
address = "Brussels, Belgium",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D18-1259",
doi = "10.18653/v1/D18-1259",
pages = "2369--2380",
}
@inproceedings{joshi2017triviaqa,
title = "{T}rivia{QA}: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension",
author = "Joshi, Mandar and
Choi, Eunsol and
Weld, Daniel and
Zettlemoyer, Luke",
editor = "Barzilay, Regina and
Kan, Min-Yen",
booktitle = "Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2017",
address = "Vancouver, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/P17-1147",
doi = "10.18653/v1/P17-1147",
pages = "1601--1611",
}
@inproceedings{petroni-etal-2021-kilt,
title = "{KILT}: a Benchmark for Knowledge Intensive Language Tasks",
author = {Petroni, Fabio and Piktus, Aleksandra and
Fan, Angela and Lewis, Patrick and
Yazdani, Majid and De Cao, Nicola and
Thorne, James and Jernite, Yacine and
Karpukhin, Vladimir and Maillard, Jean and
Plachouras, Vassilis and Rockt{\"a}schel, Tim and
Riedel, Sebastian},
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association
for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.200",
doi = "10.18653/v1/2021.naacl-main.200",
pages = "2523--2544",
}
@article{kwiatkowski2019natural,
title = "Natural Questions: A Benchmark for Question Answering Research",
author = "Kwiatkowski, Tom and
Palomaki, Jennimaria and
Redfield, Olivia and
Collins, Michael and
Parikh, Ankur and
Alberti, Chris and
Epstein, Danielle and
Polosukhin, Illia and
Devlin, Jacob and
Lee, Kenton and
Toutanova, Kristina and
Jones, Llion and
Kelcey, Matthew and
Chang, Ming-Wei and
Dai, Andrew M. and
Uszkoreit, Jakob and
Le, Quoc and
Petrov, Slav",
editor = "Lee, Lillian and
Johnson, Mark and
Roark, Brian and
Nenkova, Ani",
journal = "Transactions of the Association for Computational Linguistics",
volume = "7",
year = "2019",
address = "Cambridge, MA",
publisher = "MIT Press",
url = "https://aclanthology.org/Q19-1026",
doi = "10.1162/tacl_a_00276",
pages = "452--466",
}
@inproceedings{gao2023alce,
title = "Enabling Large Language Models to Generate Text with Citations",
author = "Gao, Tianyu and
Yen, Howard and
Yu, Jiatong and
Chen, Danqi",
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.emnlp-main.398",
doi = "10.18653/v1/2023.emnlp-main.398",
pages = "6465--6488",
}
@inproceedings{stelmakh2022asqa,
title = "{ASQA}: Factoid Questions Meet Long-Form Answers",
author = "Stelmakh, Ivan and
Luan, Yi and
Dhingra, Bhuwan and
Chang, Ming-Wei",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-main.566",
doi = "10.18653/v1/2022.emnlp-main.566",
pages = "8273--8288",
}
@inproceedings{fan-etal-2019-eli5,
title = "{ELI}5: Long Form Question Answering",
author = "Fan, Angela and
Jernite, Yacine and
Perez, Ethan and
Grangier, David and
Weston, Jason and
Auli, Michael",
booktitle = acl,
year = "2019",
url = "https://aclanthology.org/P19-1346",
doi = "10.18653/v1/P19-1346",
pages = "3558--3567",
}
@article{rubin2022qampari,
title={{QAMPARI: An Open-domain Question Answering Benchmark for Questions with Many Answers from Multiple Paragraphs}},
author={Rubin, Samuel Joseph Amouyal Ohad and Yoran, Ori and Wolfson, Tomer and Herzig, Jonathan and Berant, Jonathan},
journal={arXiv preprint arXiv:2205.12665},
year={2022},
url="https://arxiv.org/abs/2205.12665"
}
@misc{bajaj2018ms,
title={MS MARCO: A Human Generated MAchine Reading COmprehension Dataset},
author={Payal Bajaj and Daniel Campos and Nick Craswell and Li Deng and Jianfeng Gao and Xiaodong Liu and Rangan Majumder and Andrew McNamara and Bhaskar Mitra and Tri Nguyen and Mir Rosenberg and Xia Song and Alina Stoica and Saurabh Tiwary and Tong Wang},
year={2018},
eprint={1611.09268},
archivePrefix={arXiv},
primaryClass={cs.CL},
url="https://arxiv.org/abs/1611.09268"
}
@article{kocisky2018narrativeqa,
title = "The {N}arrative{QA} Reading Comprehension Challenge",
author = "Ko{\v{c}}isk{\'y}, Tom{\'a}{\v{s}} and
Schwarz, Jonathan and
Blunsom, Phil and
Dyer, Chris and
Hermann, Karl Moritz and
Melis, G{\'a}bor and
Grefenstette, Edward",
journal = "Transactions of the Association for Computational Linguistics",
volume = "6",
year = "2018",
address = "Cambridge, MA",
publisher = "MIT Press",
url = "https://aclanthology.org/Q18-1023",
doi = "10.1162/tacl_a_00023",
pages = "317--328"
}
@inproceedings{
shen2022multilexsum,
title={Multi-LexSum: Real-world Summaries of Civil Rights Lawsuits at Multiple Granularities},
author={Zejiang Shen and Kyle Lo and Lauren Yu and Nathan Dahlberg and Margo Schlanger and Doug Downey},
booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2022},
url={https://openreview.net/forum?id=z1d8fUiS8Cr}
}
@misc{zhang2024inftybenchextendinglongcontext,
title={$\infty$Bench: Extending Long Context Evaluation Beyond 100K Tokens},
author={Xinrong Zhang and Yingfa Chen and Shengding Hu and Zihang Xu and Junhao Chen and Moo Khai Hao and Xu Han and Zhen Leng Thai and Shuo Wang and Zhiyuan Liu and Maosong Sun},
year={2024},
eprint={2402.13718},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2402.13718},
}
@inproceedings{li-roth-2002-learning,
title = "Learning Question Classifiers",
author = "Li, Xin and
Roth, Dan",
booktitle = "{COLING} 2002: The 19th International Conference on Computational Linguistics",
year = "2002",
url = "https://aclanthology.org/C02-1150",
}
@article{Liu2019BenchmarkingNL,
title={Benchmarking Natural Language Understanding Services for building Conversational Agents},
author={Xingkun Liu and Arash Eshghi and Pawel Swietojanski and Verena Rieser},
journal={ArXiv},
year={2019},
volume={abs/1903.05566},
url={https://api.semanticscholar.org/CorpusID:76660838}
}
@inproceedings{casanueva-etal-2020-efficient,
title = "Efficient Intent Detection with Dual Sentence Encoders",
author = "Casanueva, I{\~n}igo and
Tem{\v{c}}inas, Tadas and
Gerz, Daniela and
Henderson, Matthew and
Vuli{\'c}, Ivan",
editor = "Wen, Tsung-Hsien and
Celikyilmaz, Asli and
Yu, Zhou and
Papangelis, Alexandros and
Eric, Mihail and
Kumar, Anuj and
Casanueva, I{\~n}igo and
Shah, Rushin",
booktitle = "Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.nlp4convai-1.5",
doi = "10.18653/v1/2020.nlp4convai-1.5",
pages = "38--45",
}
@inproceedings{larson-etal-2019-evaluation,
title = "An Evaluation Dataset for Intent Classification and Out-of-Scope Prediction",
author = "Larson, Stefan and
Mahendran, Anish and
Peper, Joseph J. and
Clarke, Christopher and
Lee, Andrew and
Hill, Parker and
Kummerfeld, Jonathan K. and
Leach, Kevin and
Laurenzano, Michael A. and
Tang, Lingjia and
Mars, Jason",
editor = "Inui, Kentaro and
Jiang, Jing and
Ng, Vincent and
Wan, Xiaojun",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)",
month = nov,
year = "2019",
address = "Hong Kong, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D19-1131",
doi = "10.18653/v1/D19-1131",
pages = "1311--1316",
}