DocSum¶
Overview¶
The DocSum example is designed to process diverse content types including text documents, spoken language (audio), and visual media (video) to generate concise summaries that capture the essence of the original material. This pipeline integrates ASR (automatic speech recognition) with an LLM to summarize the content. This example can be used to create summaries of news articles, research papers, technical documents, legal documents, multimedia documents, and other types of documents.
Purpose¶
Quick Content Understanding: Saves time by providing concise overviews of lengthy documents, enabling users to focus on essential information.
Knowledge Management: Organizes and indexes large repositories of documents, making information retrieval and navigation more efficient.
Research and Analysis: Simplifies the synthesis of insights from multiple reports or articles, accelerating data-driven decision-making.
Content Creation and Editing: Generates drafts or summaries for presentations, briefs, or automated reports, streamlining content workflows.
Legal and Compliance: Extracts key clauses and obligations from contracts or guidelines, ensuring compliance while reducing review effort.
How It Works¶
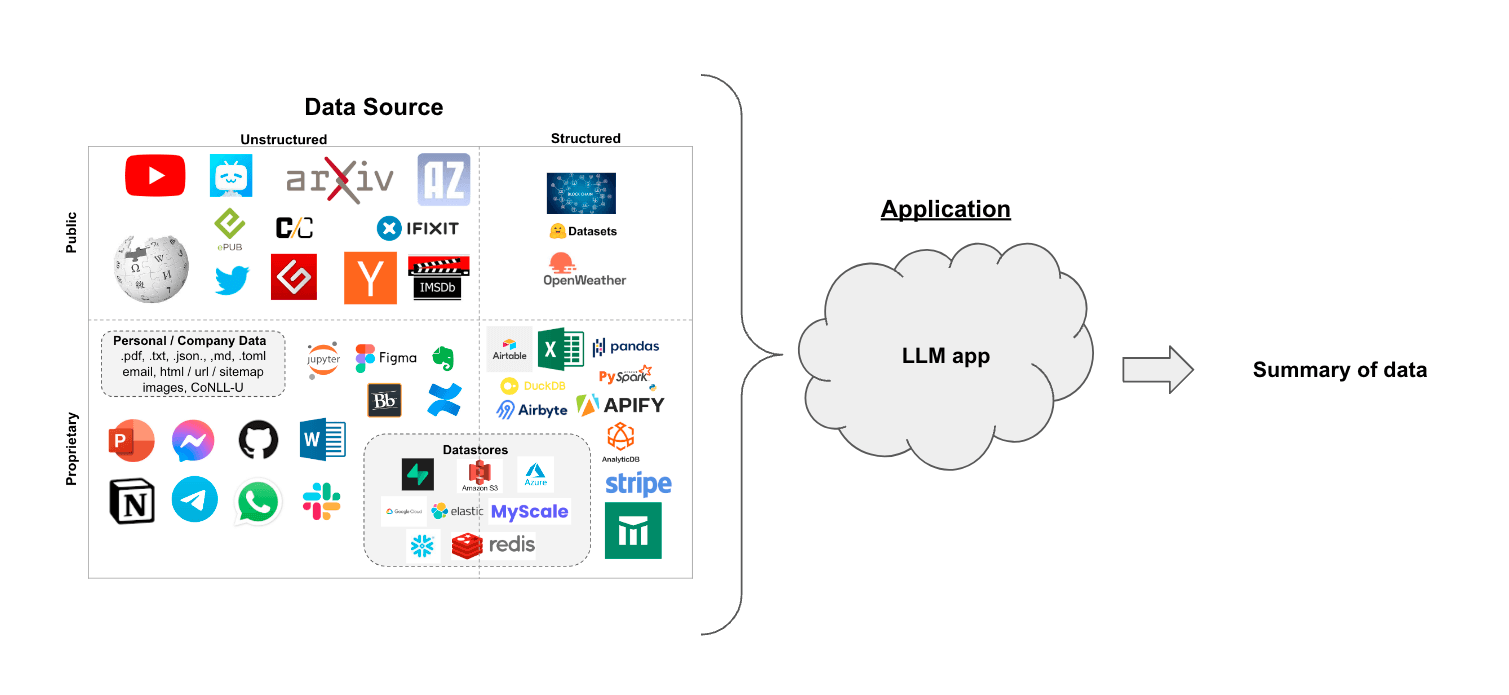
The Docsum example uses an open-source model served using a framework such as Text Generation Inference (TGI) or vLLM to construct a summary of the input provided. It can process textual, audio, and video input from a variety of sources as shown in the diagram below.
Deployment¶
Here are some deployment options, depending on the hardware and environment: