Build Mega Service of FAQ Generation on Intel Xeon Processor¶
This document outlines the deployment process for a FAQ Generation application utilizing the GenAIComps microservice pipeline on an Intel Xeon server. The steps include Docker image creation, container deployment via Docker Compose, and service execution to integrate microservices such as llm. We will publish the Docker images to Docker Hub soon, which will simplify the deployment process for this service.
🚀 Apply Intel Xeon Server on AWS¶
To apply a Intel Xeon server on AWS, start by creating an AWS account if you don’t have one already. Then, head to the EC2 Console to begin the process. Within the EC2 service, select the Amazon EC2 M7i or M7i-flex instance type to leverage 4th Generation Intel Xeon Scalable processors. These instances are optimized for high-performance computing and demanding workloads.
For detailed information about these instance types, you can refer to this link. Once you’ve chosen the appropriate instance type, proceed with configuring your instance settings, including network configurations, security groups, and storage options.
After launching your instance, you can connect to it using SSH (for Linux instances) or Remote Desktop Protocol (RDP) (for Windows instances). From there, you’ll have full access to your Xeon server, allowing you to install, configure, and manage your applications as needed.
🚀 Build Docker Images¶
First of all, you need to build Docker Images locally. This step can be ignored once the Docker images are published to Docker hub.
1. Build LLM Image¶
git clone https://github.com/opea-project/GenAIComps.git
cd GenAIComps
docker build -t opea/llm-faqgen:latest --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy -f comps/llms/src/faq-generation/Dockerfile .
2. Build MegaService Docker Image¶
To construct the Mega Service, we utilize the GenAIComps microservice pipeline within the faqgen.py Python script. Build the MegaService Docker image via below command:
git clone https://github.com/opea-project/GenAIExamples
cd GenAIExamples/FaqGen/
docker build --no-cache -t opea/faqgen:latest --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy -f GenAIExamples/FaqGen/Dockerfile .
3. Build UI Docker Image¶
Build the frontend Docker image via below command:
cd GenAIExamples/FaqGen/ui
docker build -t opea/faqgen-ui:latest --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy -f docker/Dockerfile .
4. Build react UI Docker Image (Optional)¶
Build the frontend Docker image based on react framework via below command:
cd GenAIExamples/FaqGen/ui
export BACKEND_SERVICE_ENDPOINT="http://${host_ip}:8888/v1/faqgen"
docker build -t opea/faqgen-react-ui:latest --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy --build-arg BACKEND_SERVICE_ENDPOINT=$BACKEND_SERVICE_ENDPOINT -f docker/Dockerfile.react .
Then run the command docker images, you will have the following Docker Images:
opea/llm-faqgen:latestopea/faqgen:latestopea/faqgen-ui:latestopea/faqgen-react-ui:latest
🚀 Start Microservices and MegaService¶
Required Models¶
We set default model as “meta-llama/Meta-Llama-3-8B-Instruct”, change “LLM_MODEL_ID” in following Environment Variables setting if you want to use other models.
If use gated models, you also need to provide huggingface token to “HUGGINGFACEHUB_API_TOKEN” environment variable.
Setup Environment Variables¶
Since the compose.yaml will consume some environment variables, you need to setup them in advance as below.
export no_proxy=${your_no_proxy}
export http_proxy=${your_http_proxy}
export https_proxy=${your_http_proxy}
export host_ip=${your_host_ip}
export LLM_ENDPOINT_PORT=8008
export LLM_SERVICE_PORT=9000
export FAQGen_COMPONENT_NAME="OpeaFaqGenTgi"
export LLM_MODEL_ID="meta-llama/Meta-Llama-3-8B-Instruct"
export HUGGINGFACEHUB_API_TOKEN=${your_hf_api_token}
export MEGA_SERVICE_HOST_IP=${host_ip}
export LLM_SERVICE_HOST_IP=${host_ip}
export LLM_ENDPOINT="http://${host_ip}:${LLM_ENDPOINT_PORT}"
export BACKEND_SERVICE_ENDPOINT="http://${host_ip}:8888/v1/faqgen"
Note: Please replace with your_host_ip with your external IP address, do not use localhost.
Start Microservice Docker Containers¶
cd GenAIExamples/FaqGen/docker_compose/intel/cpu/xeon
docker compose up -d
Validate Microservices¶
TGI Service
curl http://${host_ip}:8008/generate \ -X POST \ -d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":17, "do_sample": true}}' \ -H 'Content-Type: application/json'
LLM Microservice
curl http://${host_ip}:9000/v1/faqgen \ -X POST \ -d '{"query":"Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for the most popular models, including FlagEmbedding, Ember, GTE and E5."}' \ -H 'Content-Type: application/json'
MegaService
curl http://${host_ip}:8888/v1/faqgen \ -H "Content-Type: multipart/form-data" \ -F "messages=Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for the most popular models, including FlagEmbedding, Ember, GTE and E5." \ -F "max_tokens=32" \ -F "stream=False"
## enable stream curl http://${host_ip}:8888/v1/faqgen \ -H "Content-Type: multipart/form-data" \ -F "messages=Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for the most popular models, including FlagEmbedding, Ember, GTE and E5." \ -F "max_tokens=32" \ -F "stream=True"
Following the validation of all aforementioned microservices, we are now prepared to construct a mega-service.
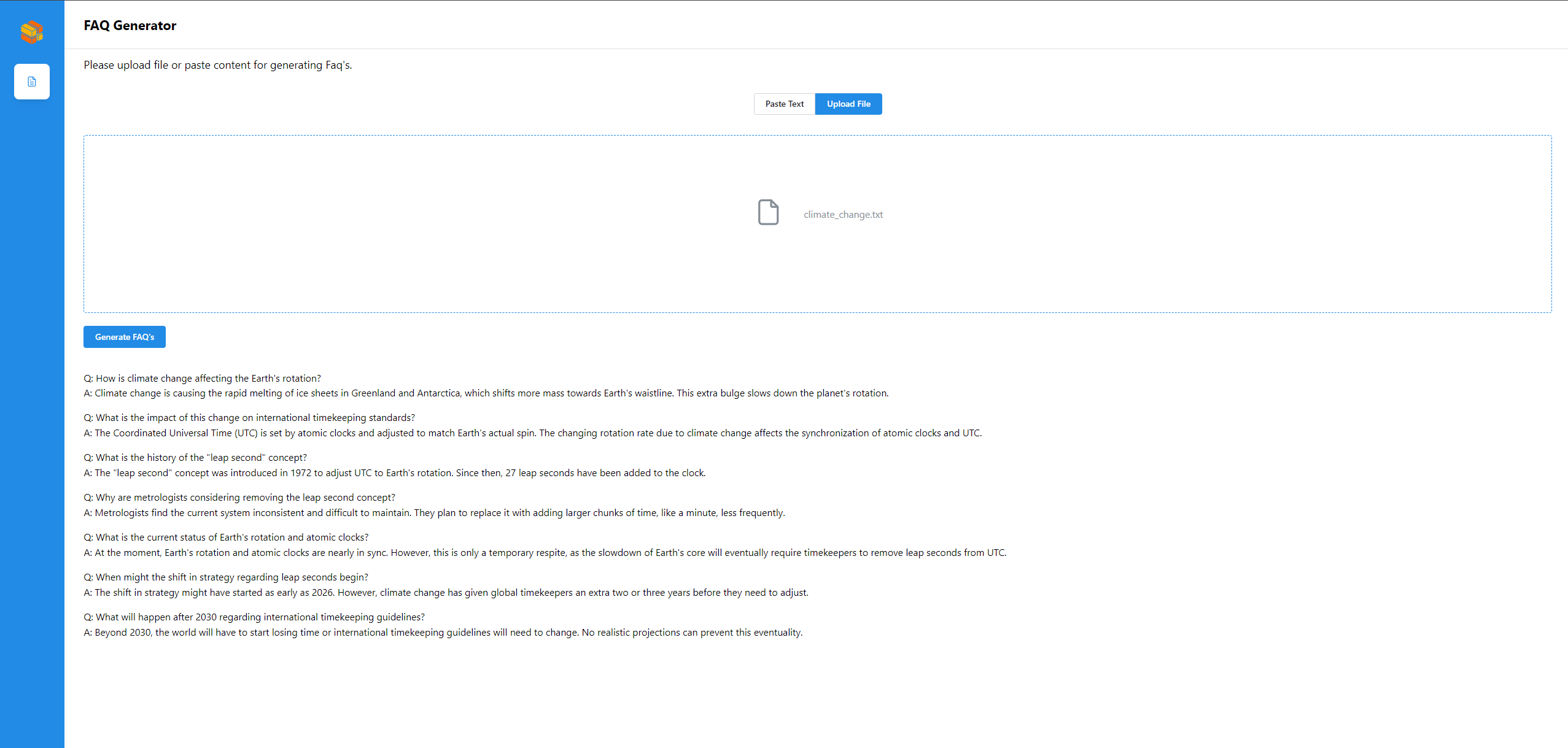
🚀 Launch the UI¶
Open this URL http://{host_ip}:5173 in your browser to access the frontend.
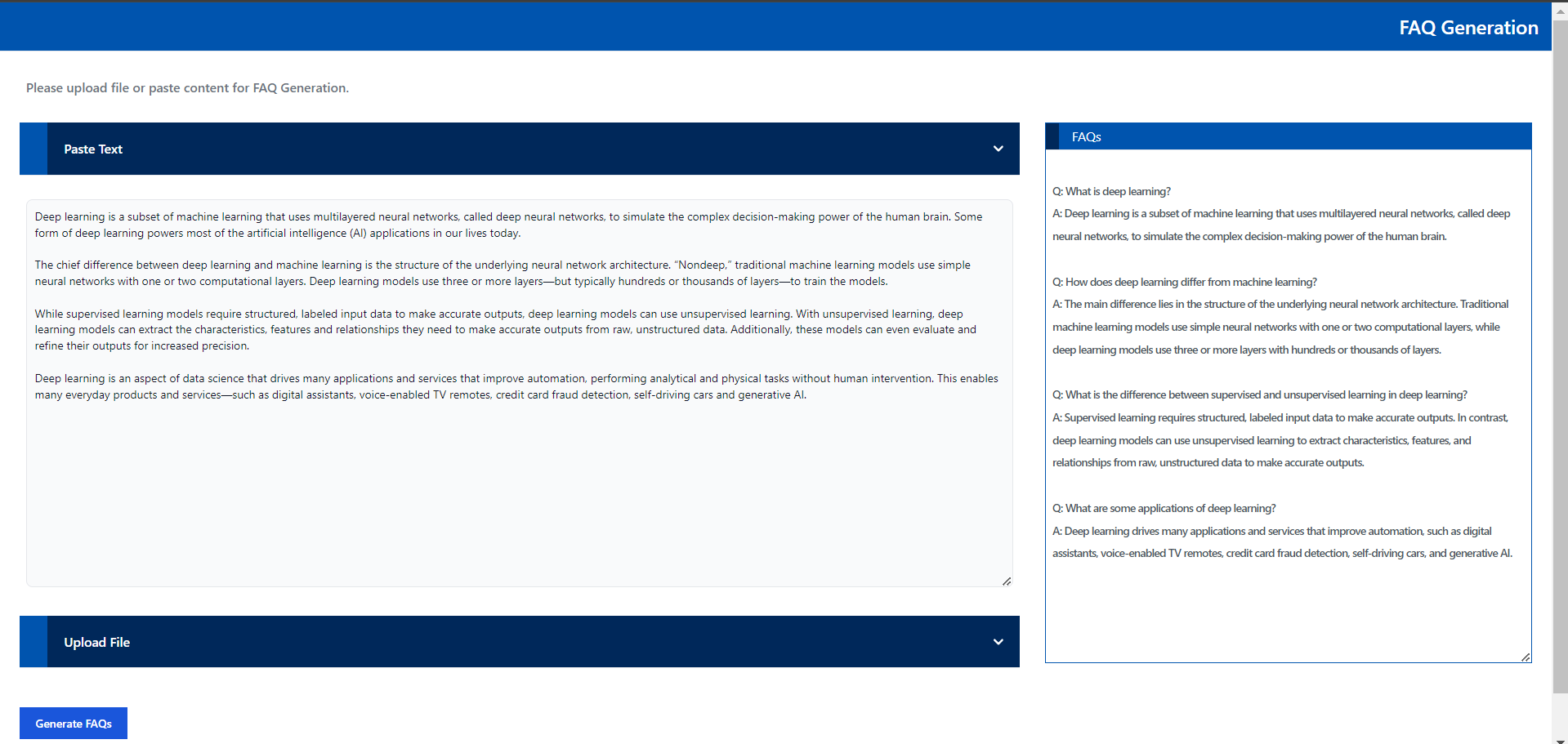
🚀 Launch the React UI (Optional)¶
To access the FAQGen (react based) frontend, modify the UI service in the compose.yaml file. Replace faqgen-xeon-ui-server service with the faqgen-xeon-react-ui-server service as per the config below:
faqgen-xeon-react-ui-server:
image: opea/faqgen-react-ui:latest
container_name: faqgen-xeon-react-ui-server
environment:
- no_proxy=${no_proxy}
- https_proxy=${https_proxy}
- http_proxy=${http_proxy}
ports:
- 5174:80
depends_on:
- faqgen-xeon-backend-server
ipc: host
restart: always
Open this URL http://{host_ip}:5174 in your browser to access the react based frontend.
Create FAQs from Text input
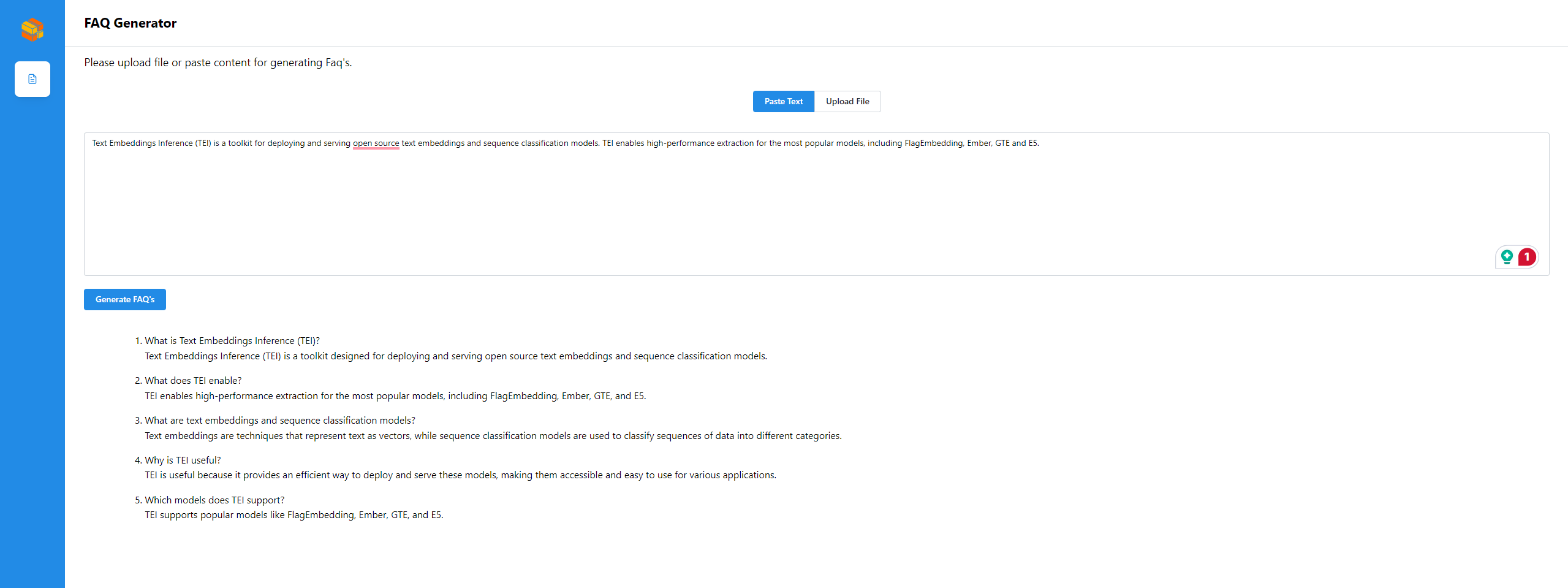
Create FAQs from Text Files