Build and deploy FaqGen Application on AMD GPU (ROCm)¶
Build images¶
Build the LLM Docker Image¶
### Cloning repo
git clone https://github.com/opea-project/GenAIComps.git
cd GenAIComps
### Build Docker image
docker build -t opea/llm-tgi:latest --build-arg https_proxy=$https_proxy --build-arg http_proxy=$http_proxy -f comps/llms/text-generation/tgi/Dockerfile .
🚀 Start Microservices and MegaService¶
Required Models¶
Default model is “meta-llama/Meta-Llama-3-8B-Instruct”. Change “LLM_MODEL_ID” in environment variables below if you want to use another model.
For gated models, you also need to provide HuggingFace token in “HUGGINGFACEHUB_API_TOKEN” environment variable.
Setup Environment Variables¶
Since the compose.yaml will consume some environment variables, you need to setup them in advance as below.
export FAQGEN_LLM_MODEL_ID="meta-llama/Meta-Llama-3-8B-Instruct"
export HOST_IP=${your_no_proxy}
export FAQGEN_TGI_SERVICE_PORT=8008
export FAQGEN_LLM_SERVER_PORT=9000
export FAQGEN_HUGGINGFACEHUB_API_TOKEN=${your_hf_api_token}
export FAQGEN_BACKEND_SERVER_PORT=8888
export FAGGEN_UI_PORT=5173
Note: Please replace with host_ip with your external IP address, do not use localhost.
Note: In order to limit access to a subset of GPUs, please pass each device individually using one or more -device /dev/dri/rendered
Example for set isolation for 1 GPU
- /dev/dri/card0:/dev/dri/card0
- /dev/dri/renderD128:/dev/dri/renderD128
Example for set isolation for 2 GPUs
- /dev/dri/card0:/dev/dri/card0
- /dev/dri/renderD128:/dev/dri/renderD128
- /dev/dri/card0:/dev/dri/card0
- /dev/dri/renderD129:/dev/dri/renderD129
Please find more information about accessing and restricting AMD GPUs in the link (https://rocm.docs.amd.com/projects/install-on-linux/en/latest/how-to/docker.html#docker-restrict-gpus)
Start Microservice Docker Containers¶
cd GenAIExamples/FaqGen/docker_compose/amd/gpu/rocm/
docker compose up -d
Validate Microservices¶
TGI Service
curl http://${host_ip}:8008/generate \ -X POST \ -d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":17, "do_sample": true}}' \ -H 'Content-Type: application/json'
LLM Microservice
curl http://${host_ip}:9000/v1/faqgen \ -X POST \ -d '{"query":"Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for the most popular models, including FlagEmbedding, Ember, GTE and E5."}' \ -H 'Content-Type: application/json'
MegaService
curl http://${host_ip}:8888/v1/faqgen \ -H "Content-Type: multipart/form-data" \ -F "messages=Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for the most popular models, including FlagEmbedding, Ember, GTE and E5." \ -F "max_tokens=32" \ -F "stream=false"
Following the validation of all aforementioned microservices, we are now prepared to construct a mega-service.
🚀 Launch the UI¶
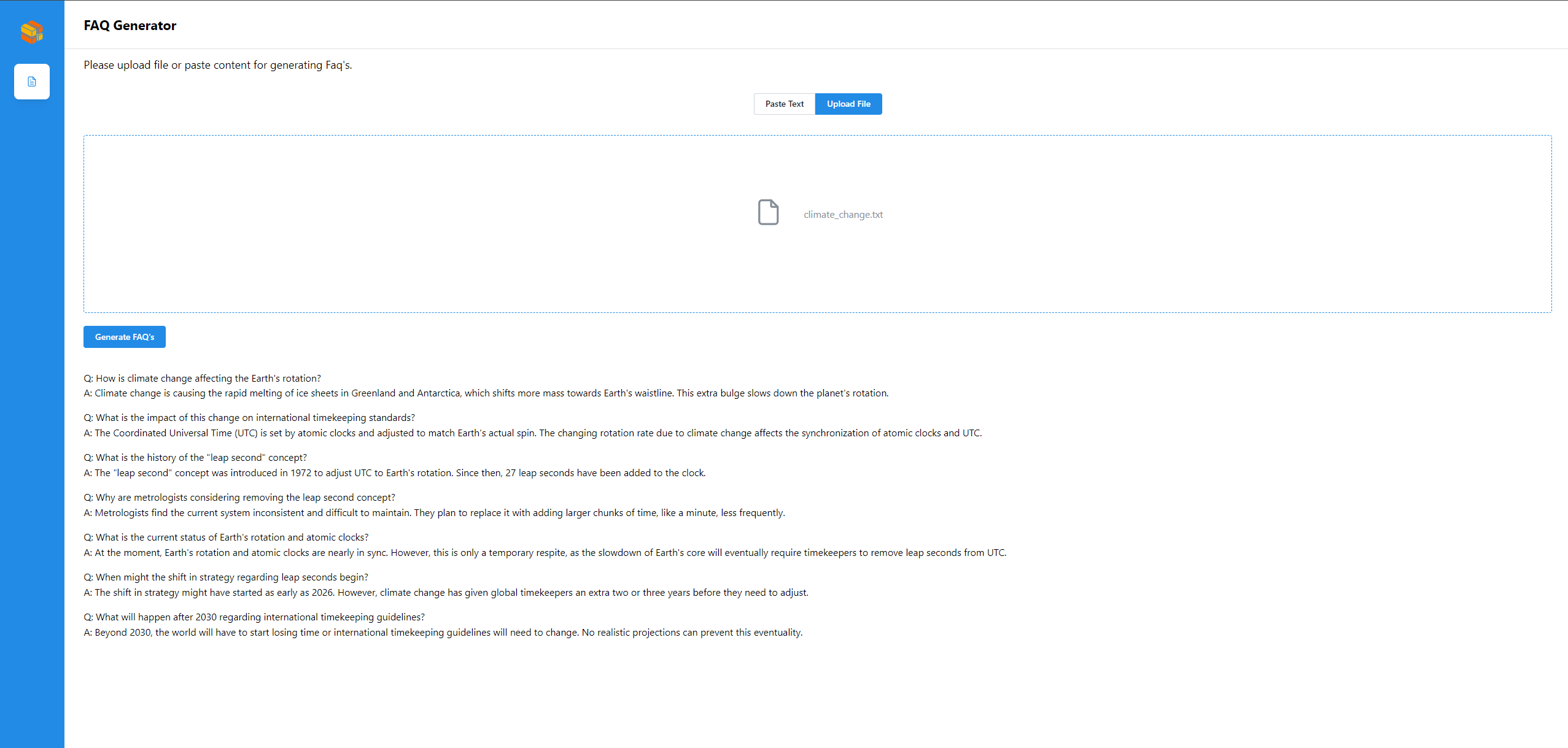
Open this URL http://{host_ip}:5173 in your browser to access the frontend.
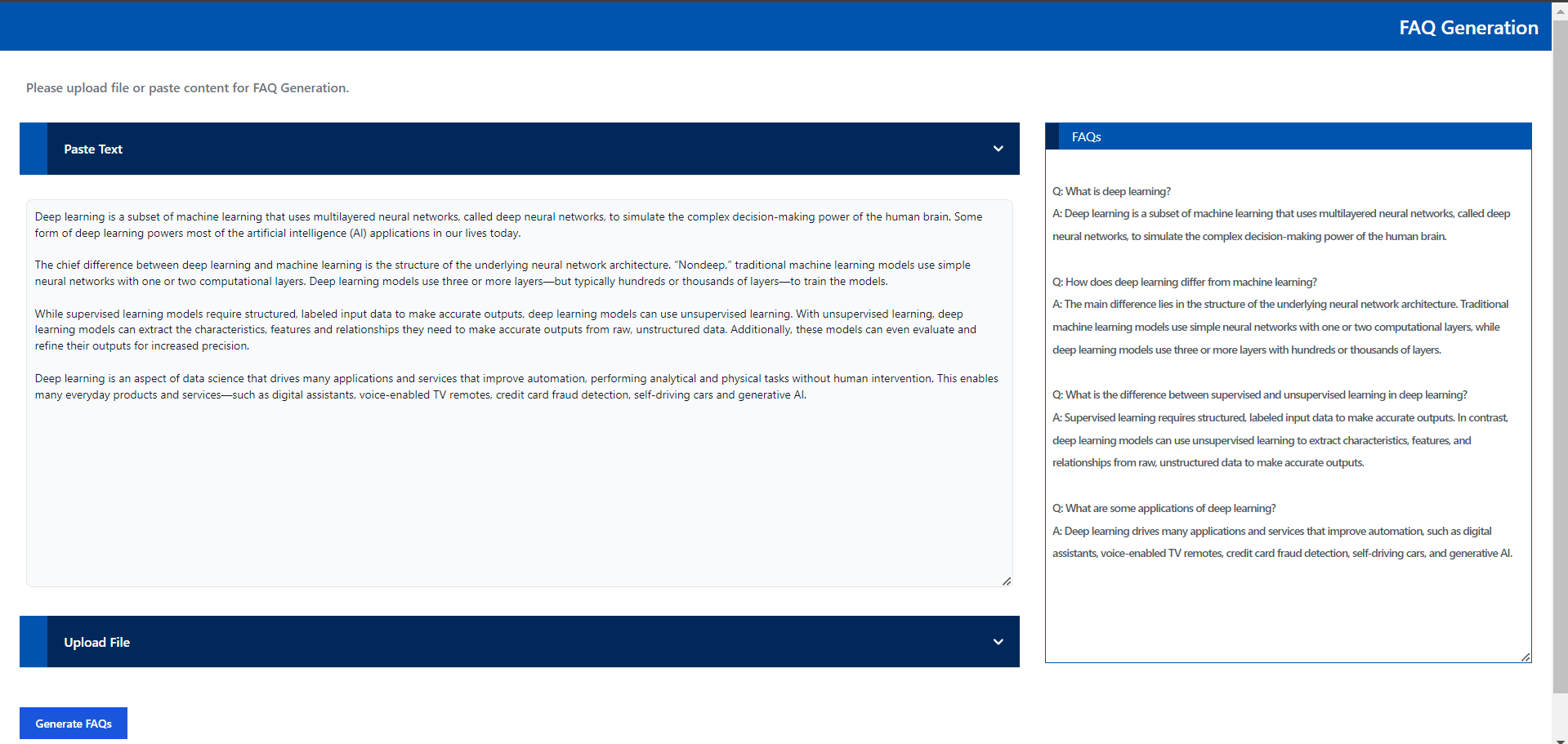
🚀 Launch the React UI (Optional)¶
To access the FAQGen (react based) frontend, modify the UI service in the compose.yaml file. Replace faqgen-rocm-ui-server service with the faqgen-rocm-react-ui-server service as per the config below:
faqgen-rocm-react-ui-server:
image: opea/faqgen-react-ui:latest
container_name: faqgen-rocm-react-ui-server
environment:
- no_proxy=${no_proxy}
- https_proxy=${https_proxy}
- http_proxy=${http_proxy}
ports:
- 5174:80
depends_on:
- faqgen-rocm-backend-server
ipc: host
restart: always
Open this URL http://{host_ip}:5174 in your browser to access the react based frontend.
Create FAQs from Text input
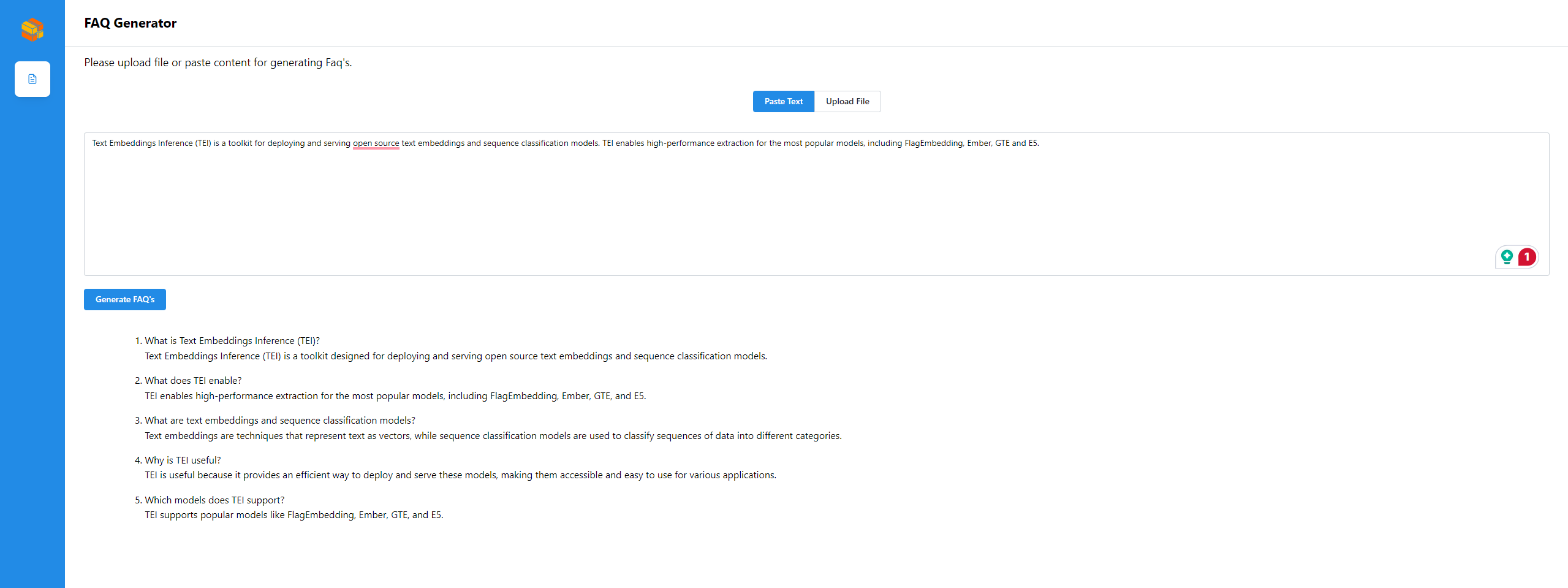
Create FAQs from Text Files