ChatQnA Application¶
Chatbots are the most widely adopted use case for leveraging the powerful chat and reasoning capabilities of large language models (LLMs). The retrieval augmented generation (RAG) architecture is quickly becoming the industry standard for chatbots development. It combines the benefits of a knowledge base (via a vector store) and generative models to reduce hallucinations, maintain up-to-date information, and leverage domain-specific knowledge.
RAG bridges the knowledge gap by dynamically fetching relevant information from external sources, ensuring that responses generated remain factual and current. The core of this architecture are vector databases, which are instrumental in enabling efficient and semantic retrieval of information. These databases store data as vectors, allowing RAG to swiftly access the most pertinent documents or data points based on semantic similarity.
🤖 Automated Terraform Deployment using Intel® Optimized Cloud Modules for Terraform¶
Cloud Provider |
Intel Architecture |
Intel Optimized Cloud Module for Terraform |
Comments |
|---|---|---|---|
AWS |
4th Gen Intel Xeon with Intel AMX |
Uses Intel/neural-chat-7b-v3-3 by default |
|
AWS Falcon2-11B |
4th Gen Intel Xeon with Intel AMX |
Uses TII Falcon2-11B LLM Model |
|
GCP |
5th Gen Intel Xeon with Intel AMX |
Also supports Confidential AI by using Intel® TDX with 4th Gen Xeon |
|
Azure |
5th Gen Intel Xeon with Intel AMX |
Work-in-progress |
Work-in-progress |
Intel Tiber AI Cloud |
5th Gen Intel Xeon with Intel AMX |
Work-in-progress |
Work-in-progress |
Automated Deployment to Ubuntu based system(if not using Terraform) using Intel® Optimized Cloud Modules for Ansible¶
To deploy to existing Xeon Ubuntu based system, use our Intel Optimized Cloud Modules for Ansible. This is the same Ansible playbook used by Terraform. Use this if you are not using Terraform and have provisioned your system with another tool or manually including bare metal.
Operating System |
Intel Optimized Cloud Module for Ansible |
|---|---|
Ubuntu 20.04 |
|
Ubuntu 22.04 |
Work-in-progress |
Manually Deploy ChatQnA Service¶
The ChatQnA service can be effortlessly deployed on Intel Gaudi2, Intel Xeon Scalable Processors and Nvidia GPU.
Two types of ChatQnA pipeline are supported now: ChatQnA with/without Rerank. And the ChatQnA without Rerank pipeline (including Embedding, Retrieval, and LLM) is offered for Xeon customers who can not run rerank service on HPU yet require high performance and accuracy.
Quick Start Deployment Steps:
Set up the environment variables.
Run Docker Compose.
Consume the ChatQnA Service.
Note: If you do not have docker installed you can run this script to install docker : bash docker_compose/install_docker.sh
Quick Start: 1.Setup Environment Variable¶
To set up environment variables for deploying ChatQnA services, follow these steps:
Set the required environment variables:
# Example: host_ip="192.168.1.1" export host_ip="External_Public_IP" # Example: no_proxy="localhost, 127.0.0.1, 192.168.1.1" export no_proxy="Your_No_Proxy" export HUGGINGFACEHUB_API_TOKEN="Your_Huggingface_API_Token"
If you are in a proxy environment, also set the proxy-related environment variables:
export http_proxy="Your_HTTP_Proxy" export https_proxy="Your_HTTPs_Proxy"
Set up other environment variables:
Notice that you can only choose one command below to set up envs according to your hardware. Other that the port numbers may be set incorrectly.
# on Gaudi source ./docker_compose/intel/hpu/gaudi/set_env.sh # on Xeon source ./docker_compose/intel/cpu/xeon/set_env.sh # on Nvidia GPU source ./docker_compose/nvidia/gpu/set_env.sh
Quick Start: 2.Run Docker Compose¶
Select the compose.yaml file that matches your hardware.
CPU example:
cd GenAIExamples/ChatQnA/docker_compose/intel/cpu/xeon/
# cd GenAIExamples/ChatQnA/docker_compose/intel/hpu/gaudi/
# cd GenAIExamples/ChatQnA/docker_compose/nvidia/gpu/
docker compose up -d
It will automatically download the docker image on docker hub:
docker pull opea/chatqna:latest
docker pull opea/chatqna-ui:latest
In following cases, you could build docker image from source by yourself.
Failed to download the docker image.
If you want to use a specific version of Docker image.
Please refer to the ‘Build Docker Images’ in Guide.
QuickStart: 3.Consume the ChatQnA Service¶
curl http://${host_ip}:8888/v1/chatqna \
-H "Content-Type: application/json" \
-d '{
"messages": "What is the revenue of Nike in 2023?"
}'
Architecture and Deploy details¶
ChatQnA architecture shows below:
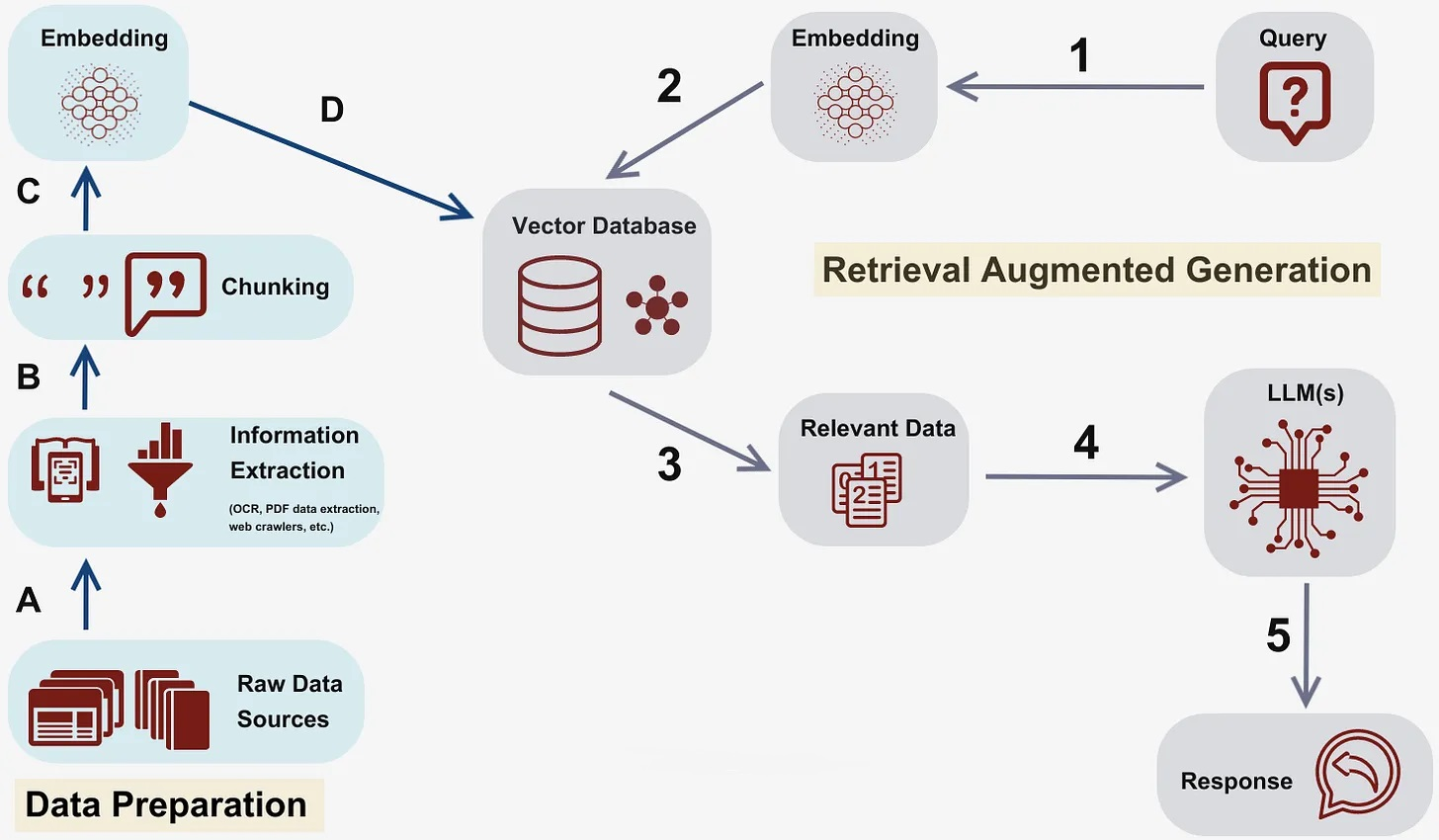
The ChatQnA example is implemented using the component-level microservices defined in GenAIComps. The flow chart below shows the information flow between different microservices for this example.
This ChatQnA use case performs RAG using LangChain, Redis VectorDB and Text Generation Inference on Intel Gaudi2 or Intel Xeon Scalable Processors. In the below, we provide a table that describes for each microservice component in the ChatQnA architecture, the default configuration of the open source project, hardware, port, and endpoint.
Gaudi default compose.yaml
MicroService |
Open Source Project |
HW |
Port |
Endpoint |
|---|---|---|---|---|
Embedding |
Langchain |
Xeon |
6000 |
/v1/embaddings |
Retriever |
Langchain, Redis |
Xeon |
7000 |
/v1/retrieval |
Reranking |
Langchain, TEI |
Gaudi |
8000 |
/v1/reranking |
LLM |
Langchain, TGI |
Gaudi |
9000 |
/v1/chat/completions |
Dataprep |
Redis, Langchain |
Xeon |
6007 |
/v1/dataprep |
Required Models¶
By default, the embedding, reranking and LLM models are set to a default value as listed below:
Service |
Model |
|---|---|
Embedding |
BAAI/bge-base-en-v1.5 |
Reranking |
BAAI/bge-reranker-base |
LLM |
Intel/neural-chat-7b-v3-3 |
Change the xxx_MODEL_ID in docker_compose/xxx/set_env.sh for your needs.
For customers with proxy issues, the models from ModelScope are also supported in ChatQnA. Refer to this readme for details.
Deploy ChatQnA on Gaudi¶
Find the corresponding compose.yaml.
cd GenAIExamples/ChatQnA/docker_compose/intel/hpu/gaudi/
docker compose up -d
Refer to the Gaudi Guide to build docker images from source.
Deploy ChatQnA on Xeon¶
Find the corresponding compose.yaml.
cd GenAIExamples/ChatQnA/docker_compose/intel/cpu/xeon/
docker compose up -d
Refer to the Xeon Guide for more instructions on building docker images from source.
Deploy ChatQnA on NVIDIA GPU¶
cd GenAIExamples/ChatQnA/docker_compose/nvidia/gpu/
docker compose up -d
Refer to the NVIDIA GPU Guide for more instructions on building docker images from source.
Deploy ChatQnA into Kubernetes on Xeon & Gaudi with GMC¶
Refer to the Kubernetes Guide for instructions on deploying ChatQnA into Kubernetes on Xeon & Gaudi with GMC.
Deploy ChatQnA into Kubernetes on Xeon & Gaudi without GMC¶
Refer to the Kubernetes Guide for instructions on deploying ChatQnA into Kubernetes on Xeon & Gaudi without GMC.
Deploy ChatQnA into Kubernetes using Helm Chart¶
Install Helm (version >= 3.15) first. Refer to the Helm Installation Guide for more information.
Refer to the ChatQnA helm chart for instructions on deploying ChatQnA into Kubernetes on Xeon & Gaudi.
Deploy ChatQnA on AI PC¶
Refer to the AI PC Guide for instructions on deploying ChatQnA on AI PC.
Deploy ChatQnA on Red Hat OpenShift Container Platform (RHOCP)¶
Refer to the Intel Technology enabling for Openshift readme for instructions to deploy ChatQnA prototype on RHOCP with Red Hat OpenShift AI (RHOAI).
Consume ChatQnA Service with RAG¶
Check Service Status¶
Before consuming ChatQnA Service, make sure the TGI/vLLM service is ready (which takes up to 2 minutes to start).
# TGI example
docker logs tgi-service | grep Connected
Consume ChatQnA service until you get the TGI response like below.
2024-09-03T02:47:53.402023Z INFO text_generation_router::server: router/src/server.rs:2311: Connected
Upload RAG Files (Optional)¶
To chat with retrieved information, you need to upload a file using Dataprep service.
Here is an example of Nike 2023 pdf.
# download pdf file
wget https://raw.githubusercontent.com/opea-project/GenAIComps/main/comps/retrievers/redis/data/nke-10k-2023.pdf
# upload pdf file with dataprep
curl -X POST "http://${host_ip}:6007/v1/dataprep" \
-H "Content-Type: multipart/form-data" \
-F "files=@./nke-10k-2023.pdf"
Consume Chat Service¶
Two ways of consuming ChatQnA Service:
Use cURL command on terminal
curl http://${host_ip}:8888/v1/chatqna \ -H "Content-Type: application/json" \ -d '{ "messages": "What is the revenue of Nike in 2023?" }'
Access via frontend
To access the frontend, open the following URL in your browser:
http://{host_ip}:5173By default, the UI runs on port 5173 internally.
If you choose conversational UI, use this URL:
http://{host_ip}:5174
Troubleshooting¶
If you get errors like “Access Denied”, validate micro service first. A simple example:
http_proxy="" curl ${host_ip}:6006/embed -X POST -d '{"inputs":"What is Deep Learning?"}' -H 'Content-Type: application/json'
(Docker only) If all microservices work well, check the port ${host_ip}:8888, the port may be allocated by other users, you can modify the
compose.yaml.(Docker only) If you get errors like “The container name is in use”, change container name in
compose.yaml.
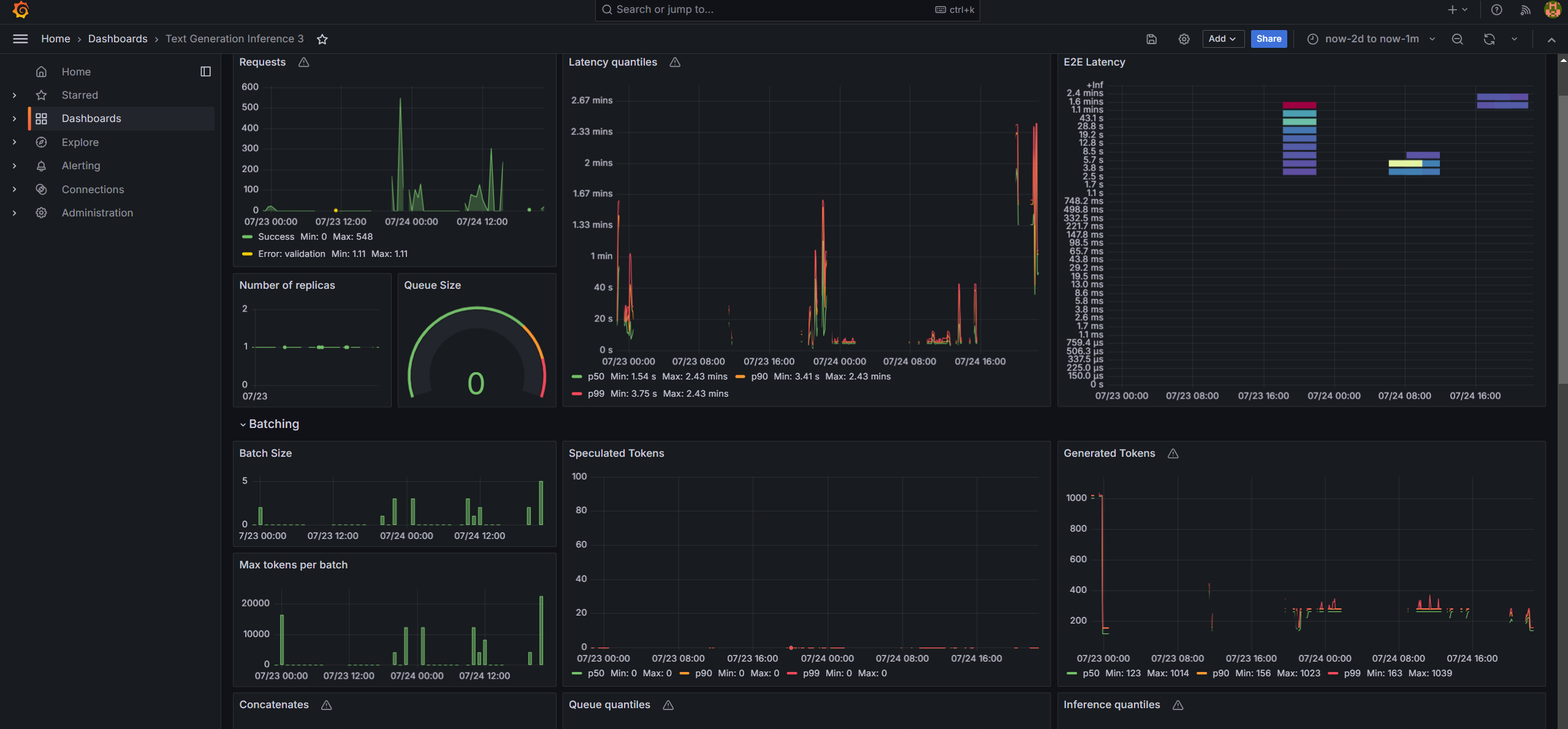
Monitoring OPEA Service with Prometheus and Grafana dashboard¶
OPEA microservice deployment can easily be monitored through Grafana dashboards in conjunction with Prometheus data collection. Follow the README to setup Prometheus and Grafana servers and import dashboards to monitor the OPEA service.